
A Design System contribution model breaks when the system team becomes either a bottleneck or a bystander, and I've watched both happen inside large product organizations.
Last week, I watched a Product Manager wait on a simple pattern review while three Designers detached the same component in Figma just to hit a sprint deadline. That's what drift looks like in real life: duplicate components, tense review threads, vague ownership, and a design system that people politely stop trusting.
The fix starts when contribution stops being a loose idea and becomes a context-aware operating model. Figr helps here by grounding design decisions in actual product reality through its Visual Context Graph, connecting live screens, flows, design system rules, product knowledge, and implementation constraints so teams can propose changes with far less guesswork.
Why Most Design System Contribution Models Fail
Most design system contribution models fail because they treat governance like process design when the core issue is trust.
I've seen the same movie more than once. The core system team starts with good intentions, then demand rises, reviews stack up, and every contribution turns into a negotiation. Product teams start hearing “not yet,” “not enough evidence,” or “we'll add it to the backlog.” After a while, they stop asking.
Then the opposite extreme shows up.
A team ships its own variant, another team copies it, a third adds a token exception, and suddenly the system is no longer a system. It's an archive of unresolved compromises.
The two failure modes everyone recognizes
The first is the fortress model. A small group owns quality, but they also own velocity, and eventually they slow both. The second is the wild west model. Everyone can contribute, but nobody can say what belongs, what duplicates an existing pattern, or what should be retired.
Both models damage the same thing: confidence.
A design system contribution model is a structured roadmap that standardizes how new elements are added to a design system, defining who can contribute, what qualifies for contribution, and the workflow from proposal to implementation, as outlined in this contribution model overview. That definition is useful, but in practice it's still incomplete unless you account for politics.
Who gets heard first?
Whose deadlines matter more?
Who absorbs the maintenance cost six months later?
Practical rule: If product teams think contribution is a favor they request from the system team, your model is already failing.
Contribution is a social contract
The strongest teams I've worked with stopped treating contribution as a submission queue. They treated it as a social contract between the people protecting consistency and the people facing market pressure every week.
That contract needs three things:
Clear access: People need to know when they can contribute directly and when they need sponsorship.
Clear thresholds: Teams need shared language for minor fixes, pattern extensions, and foundational changes.
Clear reciprocity: Contributors don't just ask for help, they help maintain what they introduce.
This is what I mean: the governance model has to absorb organizational friction, not amplify it.
If your system is struggling, the issue often isn't missing components. It's weak incentives, muddy ownership, and poor visibility into what product teams need. That's also why increasing design system adoption usually starts with contribution reform, not another documentation refresh.
The Tiered Contribution Model You Should Use Instead
The model that holds up in a large organization is the one that admits an uncomfortable truth: not every contribution deserves the same level of access, review, or ownership.
A team fixing misleading helper text should not wait behind a months-long review queue built for token changes and new primitives. A team proposing a new input pattern that could spread across five products should not merge it through the same lightweight path as a docs edit. Once those two cases share a process, politics fills the gaps. Senior teams get exceptions. Newer teams stop asking. The system team becomes a bottleneck, then a scapegoat.
A tiered model fixes that by making the social contract visible in the workflow. It sets review depth according to risk, and it makes maintenance responsibility explicit before anything ships.
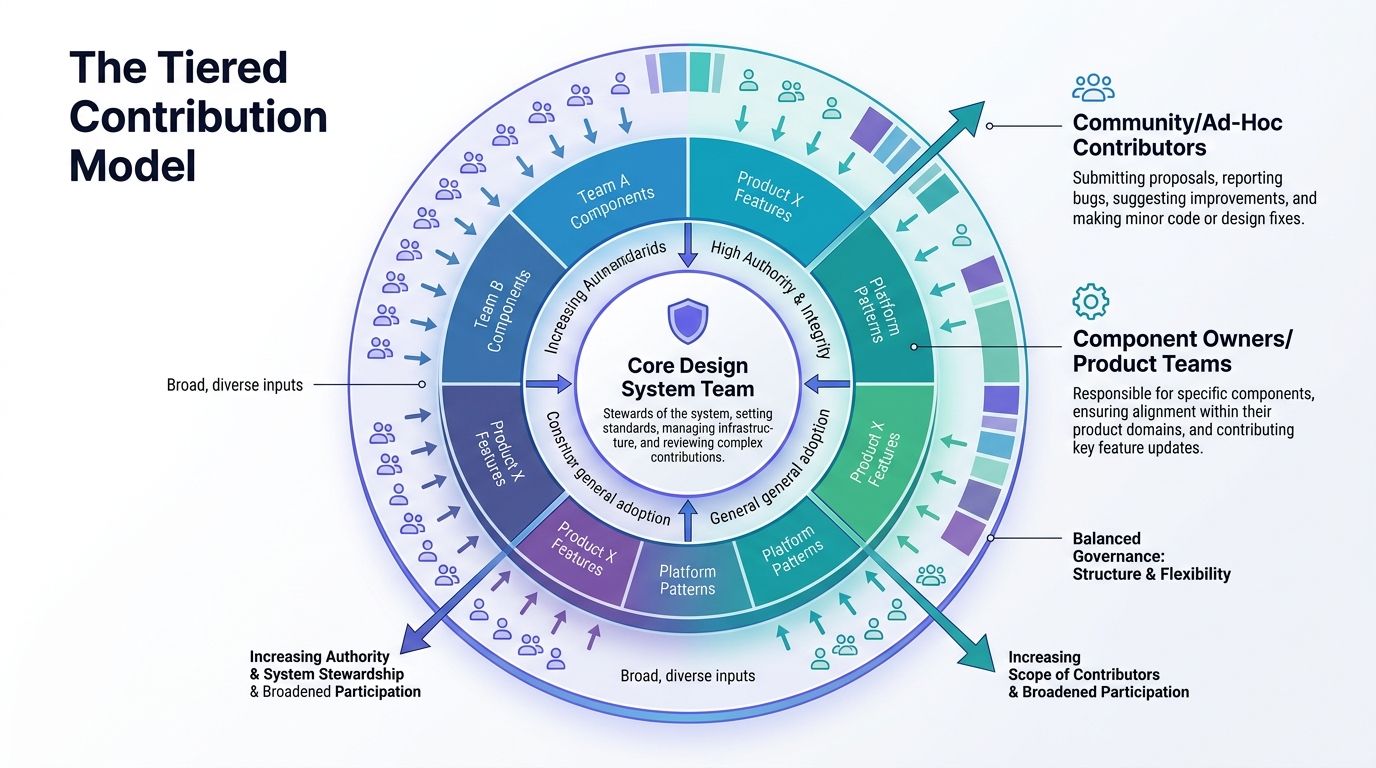
The three tiers that actually hold up
I use three tiers: Core, Federated, and Community.
Core. Protects system integrity. Scope covers tokens, primitives, architecture, and policy. Review intensity is highest.
Federated. Extends the system inside product domains. Scope covers patterns, product-area components, and mature variations. Review intensity is medium.
Community. Keeps the system useful day to day. Scope covers fixes, docs, examples, and minor guidance updates. Review intensity is light.
This structure works because it reflects how enterprise work shows up.
Some requests are foundational and expensive to reverse. Some are domain-specific and should stay close to the product teams who understand the edge cases. Some are small enough that heavy governance only teaches people to work around the system in private.
What each tier is really doing
Core exists to protect decisions that create downstream cost. If a contribution changes accessibility behavior, API logic, naming rules, token structure, or cross-platform consistency, Core owns the call. That is not gatekeeping for its own sake. It is cost control.
Federated gives product teams a legitimate lane to solve repeated problems without waiting for the central team to discover them secondhand. Enterprise systems commonly either mature or fracture in this context. If federated teams get responsibility without standards, sprawl follows. If they get standards without authority, they fork the system locally and stop contributing.
Community keeps the system from becoming precious. Documentation fixes, usage examples, content clarifications, and small quality improvements should be easy to submit and easy to merge. If these changes require a committee, contributors learn that helping is not worth the effort.
A healthy tiered model also depends on clear boundaries between design system components and tokens. Teams need to know whether they are proposing a local pattern, changing a reusable component, or touching the foundation underneath both.
Why this model lowers friction without lowering the bar
The benefit is not just operational clarity. It is political clarity.
Teams know when they can act on their own. System owners know which decisions they are expected to defend. Contributors know whether they are handing off maintenance, sharing it, or keeping it. That removes a lot of the resentment that gets mislabeled as a process problem.
I have seen the alternative too many times. A central team says yes to everything and burns out. Or it says no inconsistently, which is worse. People do not resent standards. They resent unclear standards enforced differently depending on org chart, urgency, or who already has Slack access to the system lead.
Tiering gives you a fairer answer than "submit a request and we'll see." It says: this type of change goes through this lane, with this level of evidence, and this maintenance obligation after launch. That is how you keep contribution open without pretending every contribution carries the same risk.
How to Define Your Contribution Tiers
You define contribution tiers by deciding who can change what, under which review path, and with what maintenance obligation.
The common approach to this is backward. It often begins with writing a process document. Start with risk instead. If a contribution changes foundational styles, accessibility assumptions, or code architecture, it belongs in a different lane than a small guidance correction.
A useful contribution model also distinguishes between small updates and larger changes. Minor updates, like guidance tweaks, can often start with a lightweight request path such as Slack, while major contributions, like new components, need a cross-disciplinary workflow with multiple touchpoints, as described in Ben Callahan's contribution framework.
Core tier
The Core tier should own the parts of the system that multiply downstream cost.
That usually includes:
Foundations: tokens, spacing rules, typography, color decisions
Primitives: buttons, inputs, form controls, layout building blocks
Policy: naming conventions, accessibility requirements, contribution rules
Architecture: variant strategy, API logic, deprecation rules
Use this tier when a bad decision would echo across many products.
Core contributions usually require:
An RFC: problem statement, existing alternatives, affected surfaces, migration implications
Cross-functional review: Designer, engineer, and system owner signoff
Maintenance commitment: named ownership after release
Federated tier
The Federated tier is where enterprise systems either mature or stall.
This lane is for component owners or product teams who are close to customer problems and can extend the system with real evidence. Think complex filtering patterns, workflow-specific tables, or a domain component that appears in several adjacent products.
A federated contribution should answer four questions before review:
Is the problem repeated enough to standardize
Can existing components solve it with composition
Will it create overlap with another pattern
Who owns it after launch
I'd expect peer review inside the product area first, then a lighter design system review focused on fit, naming, and reuse potential.
Community tier
The Community tier should stay easy on purpose.
Nord Health's model is useful here because it groups submissions into Minor, Medium, and Major, with Minor contributions often beginning through a Slack message or form request after a lightweight vetting step, as shown in their contributing guidance. That maps nicely to a community lane.
Community contributions often include:
Documentation fixes
Usage examples
Anti-pattern clarifications
Minor Figma cleanups
Small bug reports
These changes improve trust fast, and they help newer contributors enter the system without facing architectural review on day one.
A simple setup workflow
Step 1. Define risk bands first.
Write three levels only: foundational, reusable, minor.
Teams frequently create too many categories and then spend months debating boundaries.
Step 2. Map each band to owners.
Name the review group for each tier.
If ownership is vague, review quality becomes political.
Step 3. Publish examples, not just rules.
Show what belongs in each tier using recent changes.
People learn contribution models through precedent.
Step 4. Tie each tier to maintenance.
Every approved contribution needs a future owner.
Otherwise you've approved backlog, not a component.
Designing a Component Lifecycle from Proposal to Deprecation
A component lifecycle gives contributors predictability, and predictability is what lowers anxiety in large teams.
Without a lifecycle, every request feels custom. One proposal gets instant traction because a senior leader asked for it. Another sits in backlog limbo because nobody knows what “ready” means. A defined lifecycle fixes that by replacing status theater with visible gates.
This visual is a useful way to think about the full flow.
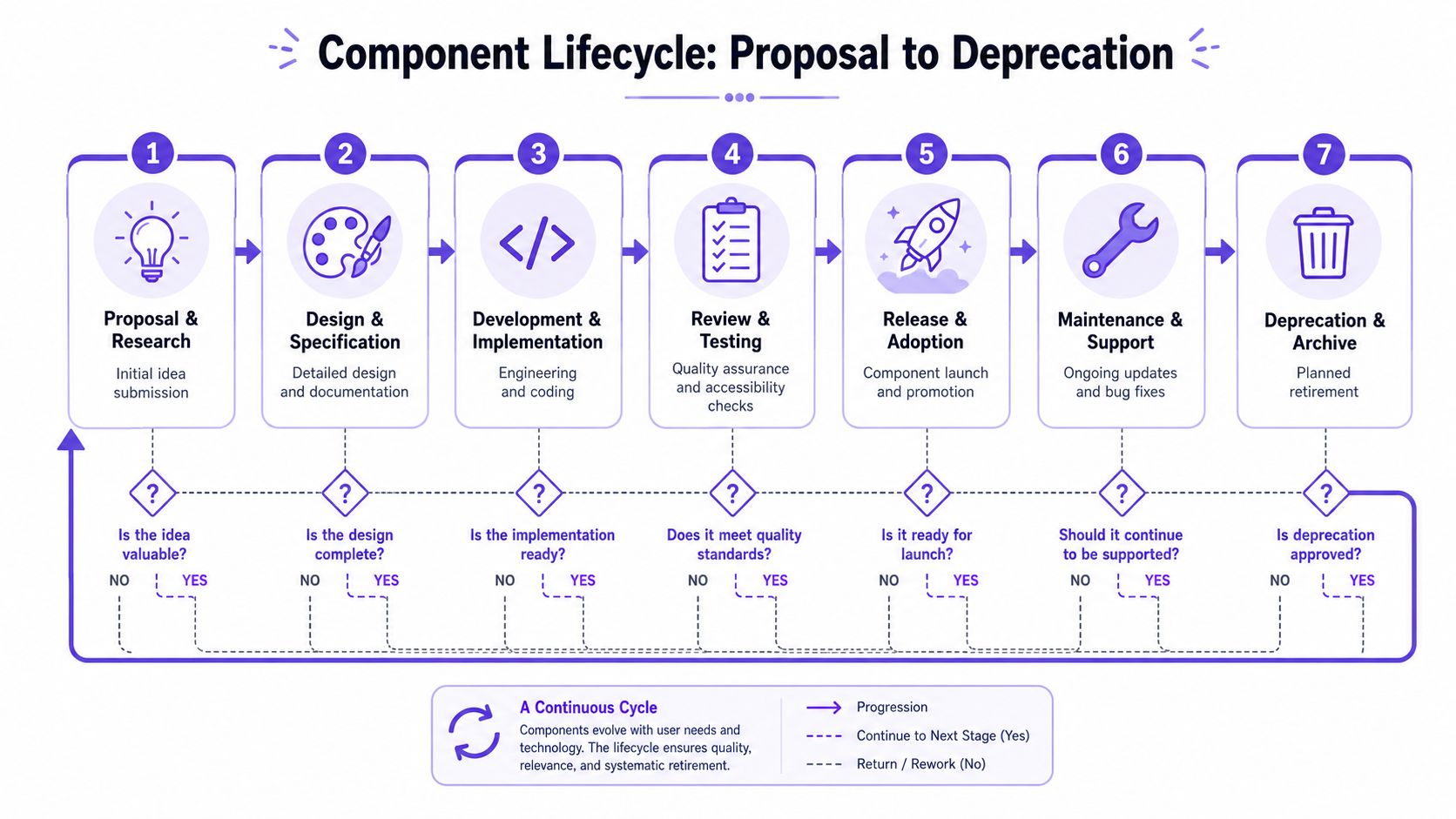
The lifecycle I would run
Step 1. Proposal.
Capture the problem before the solution calcifies.
Include the use case, screenshots, current workaround, and why existing components fail
Route it through an RFC for anything beyond a minor fix
Reject quickly if it duplicates an existing pattern or lacks a reusable use case
Step 2. Prototype.
Explore shape, behavior, and edge cases before formal commitment.
Build rough design and code explorations
Test naming, composability, and token inheritance
Review with the product team that surfaced the need
A component should still be cheap to change here.
Before a component moves further, I like teams to compare the stage gates against broader product lifecycle stages guide thinking. The same principle applies: each stage should reduce uncertainty, not just create ceremony.
This walkthrough is worth watching if you want a practical framing for lifecycle thinking.
The maturity gates that matter
Step 3. Beta.
Ship in limited production use.
Release to one or a small number of products
Track implementation friction, override behavior, and documentation gaps
Keep the API flexible enough for adjustments
Step 4. Stable.
Declare the component ready for broad adoption.
Finalize design and code
Publish guidance, examples, and anti-use cases
Confirm support model and ownership
Step 5. Deprecated.
Plan retirement before the component becomes harmful.
Mark the preferred replacement
Give teams a migration path
Set a visible archive date in documentation
What moves a component forward
The lifecycle should never be “looks polished.” It should be evidence-based.
A component advances when:
The use case is repeatable
The behavior is clear across states
The docs explain both use and misuse
Ownership survives beyond launch
The underlying economics are simple. Every unstable component pushes cost into future sprints, future handoffs, and future audits. Governance earns its keep when it prevents that delayed tax.
How Do You Enforce Quality Without Killing Momentum
You enforce quality by making requirements visible early, not by surprising contributors late.
Most contribution processes don't fail because they're too strict. They fail because they're inconsistent. One team gets a quick yes from a trusted engineer. Another spends weeks revising a proposal because the acceptance bar was never written down. That unpredictability is what kills momentum.
Use guardrails that people can see
I want three mechanisms in place from the start:
Review SLAs: Contributors should know when first feedback arrives, who gives it, and what happens if that window slips.
RFC templates: Every proposal should answer the same core questions so debate starts from shared context.
Tier-based checklists: Minor changes stay light, major changes go deeper.
A documented team turned compliance into a 32-step checklist, then split it into three phases, consolidating design, delivering design, and achieving compliance, to make the work manageable, as shown in this DesignSystems.com breakdown. I like the principle more than the exact shape.
Use the long checklist for high-impact changes. Don't force it onto a typo fix.
Review quality should improve the system, not flex authority
Good reviews ask whether the contribution fits the system and whether the system itself needs to evolve.
That second question matters.
A lot of “failed” contributions are really signals that the system has blind spots. Sometimes the team proposing the change sees a repeated problem before the core team does. A healthy review process can absorb that insight without lowering standards.
If your team is tightening component APIs and reducing overlap, this is also where software design basics help. The same thinking used to improve software design with cohesion maps neatly onto component boundaries, ownership, and maintenance cost.
Clear governance feels fast, even when it says no.
Keep the operational feedback loop short
I'd publish a review playbook with these minimum standards:
Eligibility: why this belongs in the system
Evidence: screenshots, flow context, repeated use case
Design quality: tokens, states, naming, usage rules
Engineering quality: implementation fit, maintainability, test readiness
Documentation quality: examples, anti-use cases, ownership
The teams that sustain momentum also treat review health as part of quality health. That's the operational side of Figr's continuous quality insights: quality improves when teams can see recurring failure points early instead of rediscovering them in every release cycle.
Communicating Changes and Celebrating Contributors
A contribution model survives on recognition almost as much as it survives on rules.
I learned this the hard way. A Designer shipped a thoughtful pattern fix that saved other teams time, but the only visible outcome was a merged pull request and a buried library update. Six weeks later, that same person told me system work felt invisible, so they stopped volunteering for it.
That response is rational.
Communication is part of governance
When people can't see change, they assume nothing is moving. When they can't see credit, they assume system work doesn't count.
I'd put three rituals in place:
A human-readable changelog: short, plain language updates that explain what changed, who it helps, and whether action is required
Recurring office hours: a standing time where contributors can bring rough proposals, odd edge cases, and migration questions
A showcase channel: one place to celebrate launches, docs improvements, and meaningful fixes by name
This is the zoom-out moment many teams skip. Contribution behavior follows incentives. If performance, visibility, and career growth all live in product delivery, system work will always look optional unless leaders make it legible.
Recognition lowers burnout and raises quality
Recognition also changes the emotional texture of governance.
A review process can feel adversarial when the only public moments are rejection, revision, and escalation. It feels collaborative when approved work is visible and attached to the people who made it better.
A useful recognition habit includes:
Naming the contributor
Naming the problem solved
Naming the teams helped
Naming the owner going forward
That's enough to create a memory loop inside the organization. People start to associate contribution with professional credibility rather than thankless maintenance.
People contribute more when the organization treats system work as authored work, not background labor.
The Anti-Patterns That Signal a Broken Model
Broken contribution models rarely fail in the governance doc first. They fail in the side conversations.
A product designer asks for a review, waits three weeks, then ships a local variant to hit a release date. Engineering copies the pattern, renames it, and adds one more prop to cover the edge case. Six months later, everyone complains about inconsistency, but the underlying issue is older and more human. The organization has stopped believing the system is a workable path.
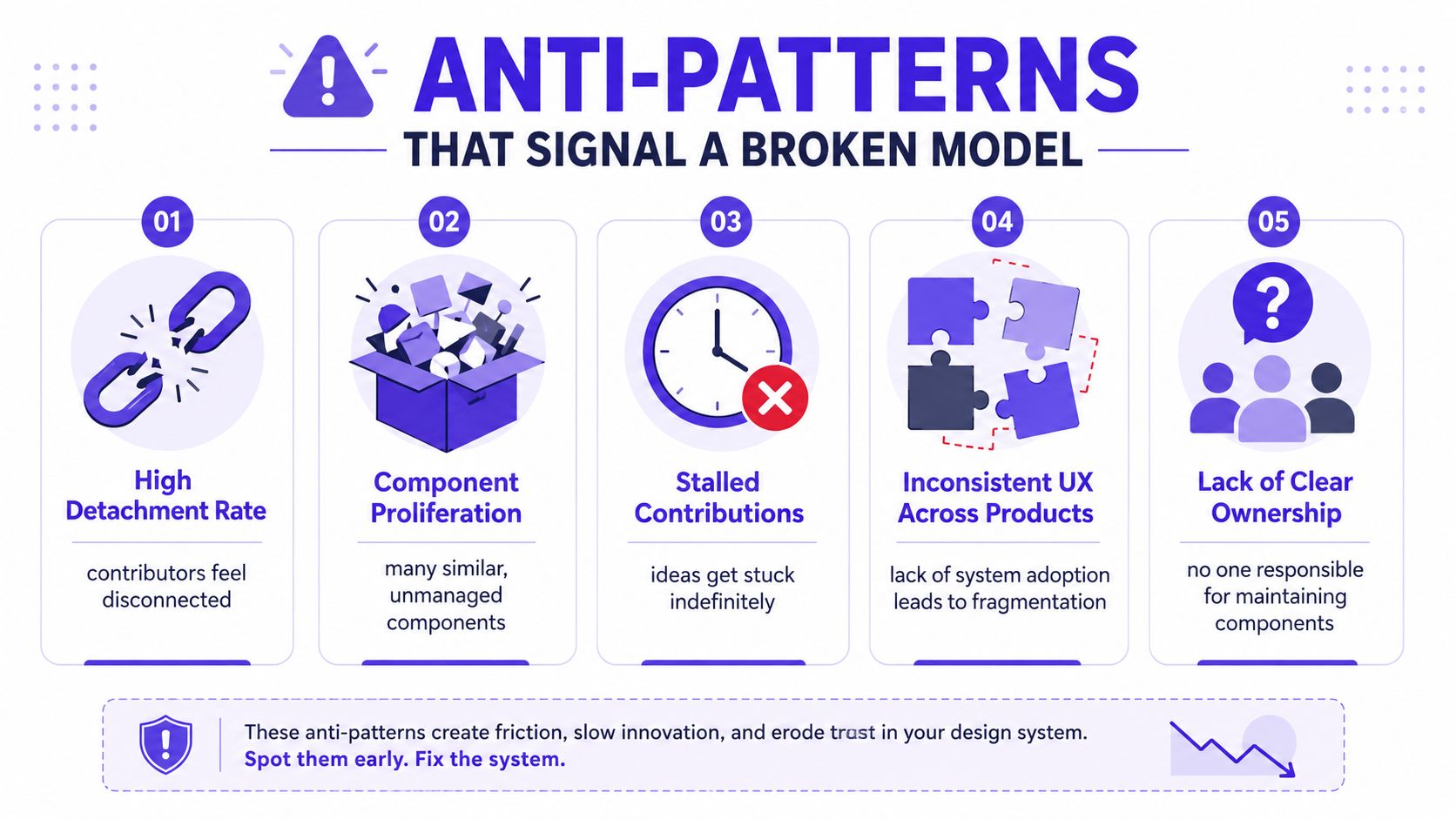
The diagnostics that matter most
The first signal I look for is detachment. If teams regularly detach components in Figma or override them heavily in code, the system is no longer meeting live product needs. That usually points to one of three failures: the component entered the system too early, its rules are too rigid, or nobody revisited it after real usage exposed gaps.
Then the second-order symptoms show up:
Shadow systems: product groups create private libraries because review feels slower than duplication
Component proliferation: near-identical patterns appear under different names, each with its own logic
Stalled contributions: proposals stay in review limbo until teams stop asking
Ownership fog: a component ships, but no one knows who fixes bugs, approves changes, or handles deprecation
These patterns are organizational signals, not just library hygiene issues. They show where trust broke.
What each anti-pattern usually means
Detached components. Signals that the system does not fit real product scenarios. Inspect eligibility criteria, flexibility, and edge states.
Shadow libraries. Signals that teams expect delay or rejection. Inspect review turnaround, decision rights, and the relationship with product teams.
Too many variants. Signals unclear component boundaries. Inspect naming rules, scope, variant policy, and retirement rules.
Frozen backlog. Signals that governance exists on paper only. Inspect triage cadence, reviewer capacity, and escalation path.
Invisible maintainers. Signals that contribution debt is accumulating. Inspect the ownership model, staffing, and support expectations.
Enterprise teams hide friction in polite ways. They stop arguing in public. They stop filing requests. They say a pattern is "temporary" while privately building around the system.
That is why artifact review is not enough. Review the behavior around the artifacts too. Teams dealing with fragmented pods and disconnected decisions usually show the same warning signs described in solving fragmented design context challenges.
The politics behind the pattern
Shadow libraries are often framed as a discipline problem. In practice, they are often a response to gatekeeping.
If a central team treats contribution like a standards tribunal, product teams will route around it. If reviewers cannot explain why one request is approved and another is blocked, people read the process as political, not principled. Once that happens, every decision gets heavier. Contributors start optimizing for self-protection instead of reuse.
Burnout follows the same path. The system team becomes the bottleneck, then the villain, then the cleanup crew.
Recognition and management habits matter here more than many leaders admit. The mechanics behind effective employee appreciation apply directly to contribution work because maintenance, review, and migration are visible only when leaders choose to make them visible.
Look for behavior, not just artifacts
Pay attention to the language in critiques, tickets, and handoff notes.
"The system won't let me" means people see the system as an external authority. "The system doesn't support this yet" means they still believe improvement is possible. That difference sounds small. It is not.
A healthy model produces debate, clear ownership, and occasional disagreement. A broken one produces avoidance.
How to Ground Contributions in Full Product Context
The best contribution models fail when teams standardize a component that solves the wrong problem.
This happens all the time in large organizations. A pattern looks reusable because it appears in three teams, but those teams may be handling different user intents, different constraints, or different business rules. Standardizing too early creates polished confusion.
The fix is to evaluate contributions in full product context, not in library isolation.
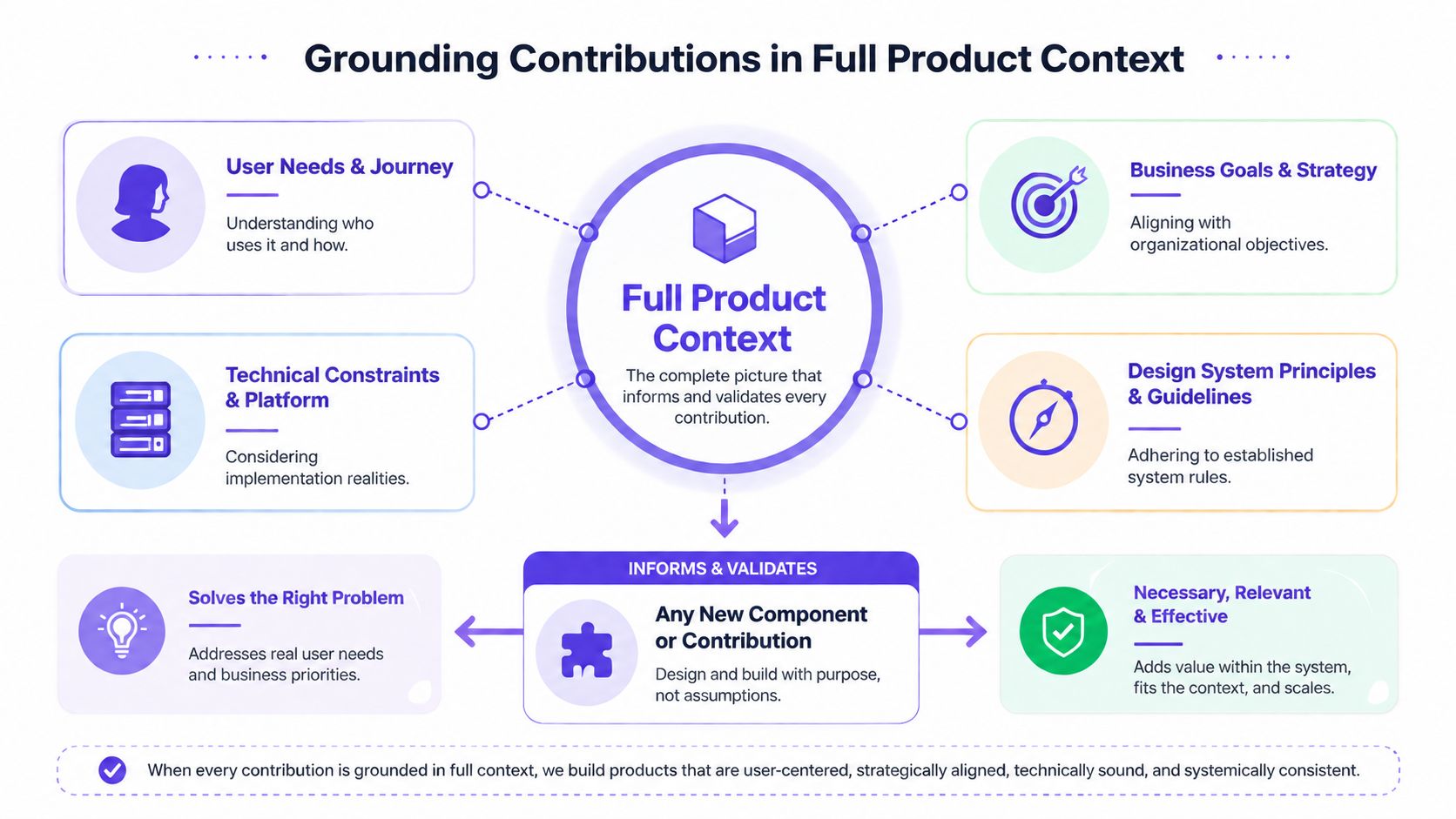
The context layers that change the decision
Figr's Visual Context Graph is useful, because it connects five layers that usually live in separate tools:
Visual context: screens, frames, and current UI structure
Behavioral context: recordings, flows, and interaction logic
Design System context: tokens, components, variants, and usage rules
Product Knowledge context: PRDs, research, and prior decisions
Implementation context: code constraints and technical realities
That mix matters because a contribution should be evaluated against the product it serves, not just the component library it might enter.
A component request makes more sense when you can inspect the surrounding flow, understand why users hit that moment, see which existing tokens apply, and account for engineering constraints before review.
Why context beats taste
I'd rather review a rough proposal with strong context than a polished mock with weak reasoning.
When teams can anchor a contribution in product evidence, they make better calls on:
Whether the problem is reusable
Whether composition can solve it
Whether the behavior differs across states
Whether the long-term maintenance cost is justified
That's also the practical answer to solving fragmented design context challenges. The issue usually isn't a lack of ideas. It's that the evidence lives in too many disconnected places for anyone to judge reuse confidently.
What changes when context is connected
A stronger context model changes contribution quality in three ways.
First, proposals arrive with sharper reasoning. Second, reviewers spend less time reconstructing background. Third, the resulting components are more likely to survive real usage because they were shaped by actual constraints from the start.
I've seen teams waste weeks debating whether a component belongs in the system when the answer was sitting in product recordings, implementation quirks, and prior decisions that nobody brought into the room together.
A design system becomes far more trustworthy when its contribution model can see beyond the component itself.
If you're trying to make contribution less political and more predictable, Figr is worth a look. It helps teams ground design work in live product context, connect design system rules to actual flows, and produce Figma-ready outputs without stripping judgment out of the process.
A scalable design system contribution model is a governance system for trust, not just a workflow for components.
The model I'd recommend is straightforward: define contribution tiers by risk, run a visible lifecycle from proposal to deprecation, use explicit quality guardrails, and make communication part of governance rather than an afterthought.
That approach works because it accepts the messy reality of enterprise design systems. People are balancing deadlines, incentives, pride, and maintenance cost all at once. Your model has to absorb those forces without collapsing into gatekeeping or chaos.
Start small. Pick one product area, define the three tiers, publish an RFC template, and set review SLAs that your team can honor. Then tune the model based on where contributors still get stuck, and try Figr.
FAQ
Good FAQ sections clear up the arguments that usually happen after rollout.
What is a design system contribution model
A design system contribution model is the operating agreement for change. It sets scope, decision rights, review paths, and maintenance ownership before a component lands in the library. Without that clarity, every proposal turns into a negotiation between product pressure and system standards.
How many contribution tiers should a large team use
Start with three. Core, Federated, and Community gives large organizations enough structure to separate high-risk assets from local patterns without creating a taxonomy nobody can remember.
I have seen teams add five or six tiers in the name of precision. It usually creates confusion, longer review times, and more debate about category labels than component quality.
Should every contribution require an RFC
No. Reserve RFCs for reusable patterns, cross-team dependencies, accessibility impact, or changes that will be expensive to reverse. Small fixes, documentation updates, and low-risk improvements should move through a lighter path.
If the paperwork is heavier than the change, contributors stop showing up.
How do I know if my model is too strict
Watch for avoidance behavior. Product teams fork components, detach from shared libraries, ship one-off variants under deadline pressure, or stop asking for review because they assume the answer will be no.
Those are governance failures, not attitude problems.
Who should own a contributed component after launch
Assign an owner before approval. The owner handles follow-up defects, usage questions, versioning decisions, and eventual deprecation. Shared ownership can work across two clearly aligned teams, but in practice it often spreads accountability so thin that nobody does the maintenance work.
That is where burnout starts.