
Product teams struggle with discovery vs delivery product management because shipping is visible, thinking is not, and AI has changed that equation faster than most operating models have caught up.
When teams don't solve that tension, they drift into a feature factory. Roadmaps fill with output, engineers build against shaky assumptions, designers rush from ticket to ticket, and everyone mistakes motion for progress. I watched a Product Manager recently spend weeks coordinating a polished release, only to realize the team had never aligned on the user problem in the first place. The work was real. The learning was missing.
What changes now is that AI can lower the cost of exploration enough to make continuous discovery practical, not aspirational. With a context-aware system like Figr, teams can turn screens, flows, research, and product history into fast artifacts for testing, so discovery stops being the work you wish you had time for and becomes part of how you ship.
What Is the Discovery vs Delivery Divide
Discovery vs delivery product management is the discipline of balancing two different jobs: deciding what to build, and building it well.
Discovery is the work of reducing uncertainty. Delivery is the work of executing with quality and reliability. Product teams need both, but they often treat one as optional depending on who is shouting loudest this quarter.
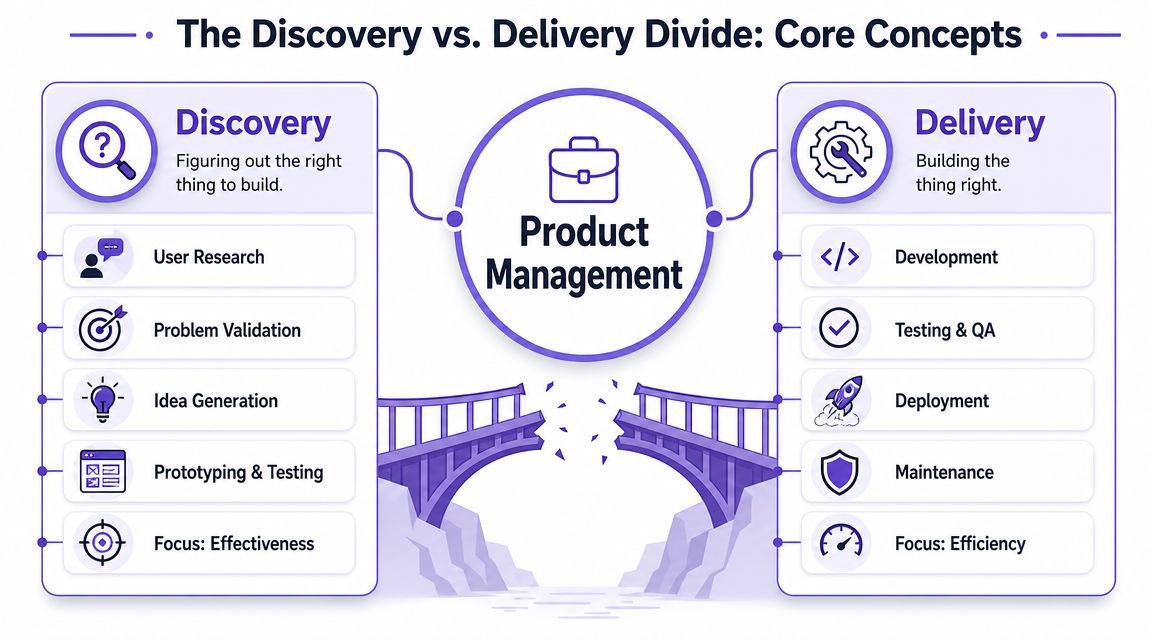
Discovery asks whether the work is worth doing
In practice, discovery is where teams investigate the problem, test assumptions, explore solution options, and gather enough evidence to move forward without guessing. A Product Manager in discovery is trying to answer questions like:
Problem clarity: Are we solving a real user problem?
Evidence quality: Do we have proof beyond stakeholder conviction?
Solution shape: Which option seems most promising to test next?
Risk exposure: What could make this fail even if we build it well?
Delivery asks whether the team can ship with confidence
Delivery begins when the team has enough confidence to commit real engineering capacity. It includes implementation, QA, release coordination, and the follow-through required after launch.
A lot of teams confuse delivery excellence with product excellence. They aren't the same thing. A beautifully shipped feature can still be the wrong bet.
Practical rule: Discovery improves effectiveness. Delivery improves efficiency. Product leadership requires both.
The historical frame matters here. A foundational milestone was the Double Diamond, formalized by the UK Design Council in 2005, which split work into alternating problem and solution spaces: discover and define, then develop and deliver, as described in this overview of the Double Diamond milestone. That model gave teams a language for something many had felt but not named. Product work moves between understanding and execution. It doesn't live in one mode.
The real divide isn't process, it's commitment timing
This is what I mean: the tension isn't between research and shipping. It's between when a team commits scarce capacity and how much uncertainty still exists at that moment.
Teams get into trouble when discovery is treated as a kickoff workshop and delivery is treated as the actual work. That's how requirements get tossed over a wall and everyone pretends the hard decisions were already made.
A healthier view is simpler. Discovery narrows uncertainty before commitment. Delivery scales commitment once confidence is good enough.
That sounds obvious.
In most companies, it still isn't how work operates.
Why Do Most Teams Get Stuck in a Feature Factory
A common pitfall is getting stuck in a feature factory because delivery metrics are easier to defend than discovery learning.
Velocity shows up in dashboards. Release dates fit neatly into planning decks. Discovery creates better decisions, but better decisions are harder to count in the moment, especially when executives want predictability by Friday.
I have seen this pattern in healthy companies and messy ones. A roadmap item gets approved because it sounds plausible. The team builds it under pressure. After launch, usage is weak, edge cases appear late, and someone reframes the effort as a learning experience. That phrase often means the team paid tuition for a question they should have answered earlier.
The incentives tilt toward shipping
Most organizations reward visible progress. Shipping creates artifacts people can point to. Discovery creates reduced risk, better framing, and decisions that prevent bad work from happening. The catch is that prevented waste rarely gets applause.
At scale, this becomes an economics problem.
Leaders ask for certainty because budgets are finite. Teams respond by turning assumptions into scope. Engineering gets dragged into solving problems that were never validated. Design gets used as a service layer for roadmap commitments that are already politically fixed.
The result is familiar:
Backlogs swell: Teams keep adding work faster than they invalidate old ideas.
Rework multiplies: Gaps surface after implementation, when changes are slower and more expensive.
Ownership blurs: Stakeholders confuse requests with evidence.
Learning decays: Insights live in call notes, decks, and scattered files nobody reopens.
That hidden waste is why the cost of rework matters so much in product organizations.
Separate teams often make the problem worse
One of the cleaner warnings on this topic comes from LogRocket's analysis of discovery and delivery, which argues that splitting the work into separate teams creates "lack of accountabilities," "unnecessary handovers," and "waterfall effect" in practice, while recommending one team own both streams end to end in its discussion of discovery and delivery ownership.
That lines up with what many Product Managers feel but struggle to articulate. The moment discovery becomes somebody else's job, delivery starts consuming assumptions instead of evidence.
Feature factories don't happen because teams are lazy. They happen because the system makes shipping easier to justify than learning.
The human cost is real too
A designer ends up polishing flows no one has pressure-tested. An engineer inherits avoidable ambiguity. A Product Manager becomes the translator between urgency above and uncertainty below. Burnout enters through that gap.
And then the team says they don't have time for discovery.
That's usually the clearest sign they need it most.
How to Run Discovery and Delivery in Parallel
Healthy product teams run discovery and delivery in parallel so learning keeps pace with shipping.
The strongest modern framing comes from SVPG: discovery should run alongside delivery, using fast customer feedback, opt-in testing, prototypes, and continuous refinement rather than being treated as a one-time front-end phase, as outlined in this piece on continuous discovery vs delivery.
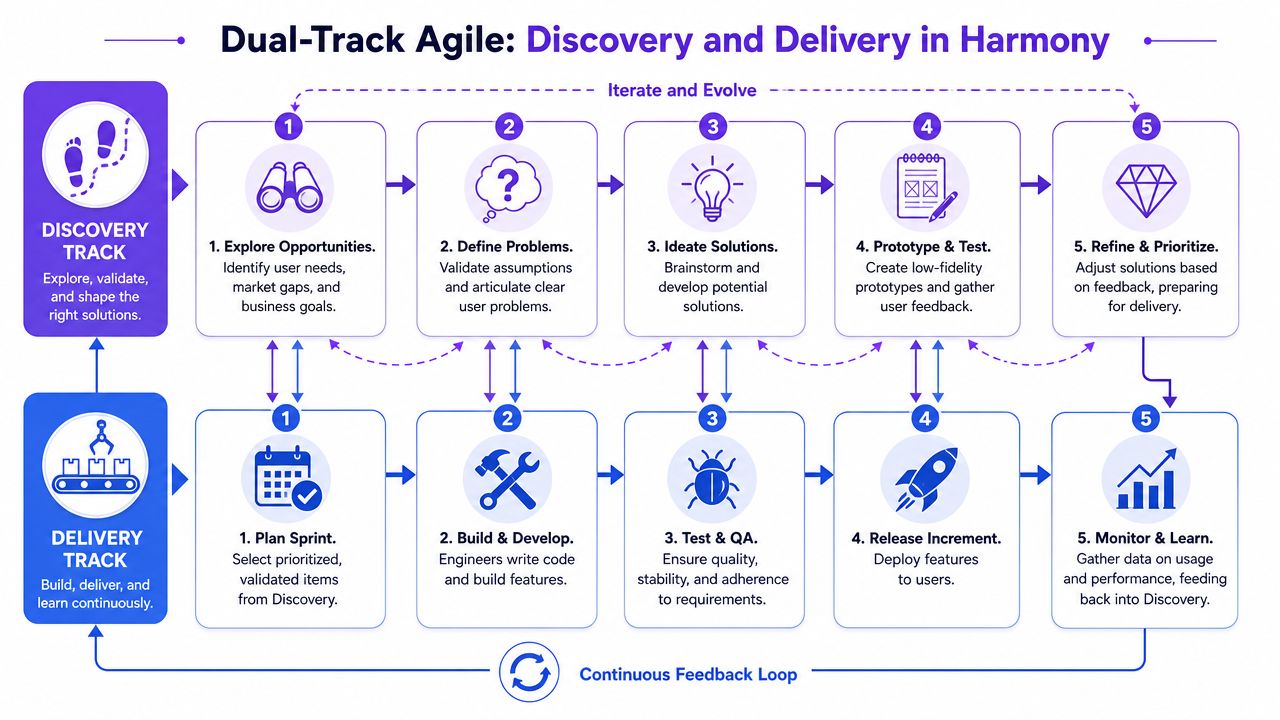
One team, two rhythms
Dual-track work isn't about creating a discovery department and a delivery department. It works best when one cross-functional team owns both.
The discovery track explores upcoming opportunities. The delivery track executes validated work already ready for build. The two tracks talk constantly. One feeds the other.
A practical weekly rhythm often looks like this:
Discovery work this week: Customer conversations, prototype reviews, analytics checks, edge case mapping, assumption testing
Delivery work this week: Sprint execution, implementation reviews, QA follow-up, release preparation, post-launch observation
Shared moments: Prioritization, tradeoff decisions, design critiques, readiness calls, lessons from recent releases
That rhythm is hard to maintain if your backlog is split across disconnected systems. Teams do better when they're managing product backlogs and design tasks in one operating flow instead of forcing handoffs between tools and owners.
A helpful visual can make the pattern easier to internalize.
What parallel work actually looks like
The failure mode here is common. Teams hear "parallel" and think "do everything at once." That's chaos. Parallel means the team is learning just ahead of commitment, not trying to validate ten unrelated ideas while shipping a critical release.
Use this operating pattern:
Discovery track stays one step ahead
Explore the next problem before it becomes a build commitment
Test assumptions while the delivery team finishes current work
Delivery track consumes de-risked items
Build what has enough evidence behind it
Keep implementation feedback flowing back to discovery
Both tracks share decision makers
Product Manager, designer, and engineering lead review evidence together
Nobody gets to throw requirements over a wall
Working rule: If delivery learns something that changes the problem, discovery resumes immediately. The tracks are parallel, not isolated.
The payoff is calmer execution
Teams that run this way don't become slower. They become less surprised.
Roadmaps still change. Markets still move. But the backlog gets cleaner because each item has survived some contact with reality before engineering commits. That doesn't eliminate risk. It lowers the expensive kind.
What Is the Right Balance for Your Team
The right balance between discovery and delivery should match the cost of being wrong.
A team improving a familiar workflow can spend more time in delivery because the problem is already well understood. A team entering a new market or changing core user behavior needs more discovery because the expensive mistakes happen before a line of code ships. The balance changes with the work.
The useful question is not, "What ratio do strong product teams use?" It is, "Where is uncertainty still high enough to create waste if we commit too early?"
Use ratios as a warning sign
A discovery-heavy split can be healthy if the team is working through unclear needs, new behaviors, or risky solution bets. A delivery-heavy split can also be healthy if the work is incremental and the evidence is already solid. The problem starts when the split is driven by habit instead of risk.
I have seen teams spend nearly all of their time shipping because delivery is easier to schedule, easier to explain to stakeholders, and easier to measure on a roadmap. Then they pay for it later with weak adoption, rework, and features nobody wants to defend six weeks after launch.
A ratio helps as a conversation starter. It should not become policy.
A new market with unclear user need deserves more discovery. An existing workflow with known pain points deserves more delivery.
A major behavior change or risky redesign deserves more discovery. A small reliability or usability fix deserves more delivery.
Conflicting stakeholder opinions deserve more discovery. Clear evidence with low ambiguity deserves more delivery.
Product maturity changes the mix
Early-stage teams usually need more discovery because they are still learning the problem, the language users use, and what good looks like. Mature products often shift more capacity into delivery because the unknowns are narrower and the team has stronger feedback loops from production.
That said, maturity can create false confidence. Established products still need serious discovery when the team is tackling a new segment, changing pricing and packaging, redesigning a core flow, or introducing AI into a job users already perform in a specific way. Familiar codebases do not remove market risk.
Use four checks before deciding the mix:
User uncertainty: Is the problem clear and important?
Behavior uncertainty: Do we understand current habits and workarounds?
Solution uncertainty: Have we tested enough options to avoid locking in too early?
Constraint uncertainty: Have design, engineering, and go-to-market surfaced the actual limits?
The blocker is no longer time alone
This is the shift many teams have not fully absorbed yet. Discovery used to be treated like a luxury because exploration was slow and expensive. Research took time. Design variations took time. Synthesis took time. So teams defaulted to delivery and told themselves they would learn after launch.
AI is changing that economic equation.
When tools reduce the cost of generating concepts, comparing flows, and documenting what the team has learned, the old excuse gets weaker. "We don't have time for discovery" increasingly means "we have not changed how we work." Always discovering is becoming practical, not aspirational.
A healthy balance protects speed and judgment
Teams get into trouble at both extremes. Too little discovery creates output without conviction. Too much discovery creates motion without commitment.
Strong product leadership keeps both in check. Increase discovery when the next decision could create expensive waste. Increase delivery when the remaining questions are small enough that building is the fastest way to learn.
That is the balance. It is not a fixed percentage. It is a disciplined response to uncertainty, adjusted now that the cost of exploration is dropping fast.
Deciding When to Stop Discovering and Start Delivering
You should stop discovering and start delivering when uncertainty has dropped enough that the team can build with confidence.
That sounds subjective, but it becomes manageable once you define what kind of uncertainty still matters. Mind the Product offers the clearest practical lens here: teams should begin with discovery when uncertainty is high and move to delivery only once evidence reduces risk enough to justify commitment, as explained in its framework for choosing discovery or delivery.
Use risk, not gut feel
Most Product Managers don't need more permission to "do discovery." They need a rule for when enough is enough.
Use assumptions as the unit of decision. If an assumption can sink the outcome, test it before engineering scales effort around it.
The assumptions usually fall into familiar buckets:
Value risk: Will users care enough?
Usability risk: Can they understand and complete the flow?
Feasibility risk: Can the team build and support it?
Viability risk: Does it fit the business and product strategy?
A simple threshold for moving forward
Use this process before moving work into committed delivery.
Step 1. List the goal-critical assumptions.
Write down the few beliefs that must be true for the work to succeed.
Ignore nice-to-know questions. Focus on what could invalidate the effort.
Step 2. Rank the assumptions by danger.
Sort them by impact and uncertainty.
The riskiest assumptions deserve the cheapest test first.
Step 3. Design lightweight tests.
Use methods that fit the question:
For value questions: Interviews, demand tests, opt-in prompts
For usability questions: Clickable prototypes, task-based reviews
For feasibility questions: Technical spikes, architecture review
For viability questions: Stakeholder review, policy or operational checks
Step 4. Define your evidence threshold.
Agree in advance what would count as enough confidence.
That could be clear user comprehension, repeated problem validation, or engineering confidence that the path is realistic.
Step 5. Move only what is de-risked enough.
Send the work into delivery when the major unknowns are narrow enough that iteration can happen inside the build, not before it.
If you can't name the assumptions, you're not ready to debate scope.
Confidence beats ceremony
I have seen teams hold long discovery phases that produced artifacts but no decisions. I have also seen teams rush into sprints because everyone was tired of talking. Both are forms of avoidance.
Good discovery ends in commitment. Good delivery begins with earned confidence.
That's the threshold that matters.
AI Is Shrinking the Cost of Exploration
AI is shrinking the cost of exploration by making testable product artifacts faster to create, revise, and compare.
For years, the practical blocker to continuous discovery wasn't theory. It was cost. It took considerable time to turn a half-formed idea into a user flow, prototype, edge case map, or reviewable concept that looked enough like the actual product to generate meaningful feedback.
That cost is collapsing.
Why this changes the economics of product work
When exploration gets cheaper, Product Managers can ask better questions more often. Designers can test variations without redrawing the world. Engineers can review proposed flows earlier, when changes are still affordable. Discovery stops competing with delivery for oxygen and starts feeding it.
This matters even more around launch planning. If you're pressure-testing a new feature, a practical checklist of essential launch steps can help teams connect discovery outputs to release readiness instead of treating launch as a separate ceremony.
The wider point is larger than any one process. AI changes the unit economics of uncertainty reduction. That's a big deal because feature factories are often funded by friction. When exploring is slow, teams skip it. When exploring gets faster, the excuse weakens.
Context matters more than speed
Fast output alone doesn't fix discovery. Generic screens and shallow prompts create false confidence. The useful shift comes when AI can work from real product context, existing flows, design systems, prior decisions, and behavior signals.
That's why the conversation around artificial intelligence in product management is getting more concrete. The best use isn't replacing judgment. It's compressing the mechanical work around exploration so human judgment can show up earlier and more often.
Consider a realistic workflow. A team wants to rethink a checkout experience. Instead of starting from a blank whiteboard, they review the live flow, inspect failure points, generate multiple concept directions, and compare edge cases before anything is committed. A gallery example such as Shopify checkout redesign work on Figr's gallery shows the shape of that kind of exploration, where the point is to explore futures grounded in an existing product rather than generate disconnected templates.
The old excuse is wearing thin
The old line was, "We'd love to do more discovery, but we need to ship."
That was often true.
Now the harder question is this: if AI can help your team create realistic artifacts quickly, what exactly is still preventing discovery from happening every week?
How to Use Figr to Accelerate Your Discovery Loop
The most useful way to accelerate discovery is to remove the manual work between an insight and a testable artifact.
A context-aware AI design tool for product teams can be practical. Figr ingests live screens, Figma files, design systems, PRDs, research, analytics, and implementation constraints, then generates artifacts like flows, edge case maps, test scenarios, and Figma-ready prototypes grounded in the product's real context.
Start where teams usually get blocked
The common bottlenecks aren't mysterious. They show up in the same places across product organizations.
- A Product Manager knows the problem, but not the full flow
Live Product Capture helps map current screens, hierarchy, and likely states so the team can review what exists before proposing changes.
A designer needs to test an idea, but the prototype queue is full
High-fidelity prototype generation gives the team something realistic enough to react to without waiting for a full manual build.
An engineering lead worries the concept hides ugly state complexity
Edge case mapping surfaces states, product risks, and design implications early enough to discuss before implementation.
Research, analytics, and PRDs live in different places
A shared context layer lets the team pull those inputs into the same working loop instead of reconstructing history in every meeting.
A practical workflow that keeps learning moving
Use it like this:
Step 1. Capture the current product reality.
Pull in live screens, recordings, or Figma files.
Start with what users experience, not what the roadmap says exists.
Step 2. Load written and behavioral context.
Add PRDs, research notes, walkthroughs, and analytics observations.
This keeps the team from designing in a vacuum.
Step 3. Generate candidate flows and prototypes.
Explore alternative paths, state handling, and interaction models.
Keep the work close enough to reality that stakeholders can give useful feedback.
Step 4. Review with product, design, and engineering together.
Use the generated artifacts to discuss tradeoffs:
User friction: Where confusion might appear
System complexity: Which states are costly to support
Scope choice: What deserves build priority now
Step 5. Turn learning into delivery-ready artifacts.
Move from testable concepts into acceptance criteria, state diagrams, and Figma-ready screens.
Field note: Discovery gets dramatically easier when the first draft is no longer the expensive part.
What improves when the loop tightens
The outcome isn't just faster mockups. The win is shorter distance between question and evidence. Product teams can test more ideas, reject weak ones earlier, and enter delivery with fewer unresolved surprises.
That is how discovery becomes a habit instead of a workshop.
Building a System of Record for Product Knowledge
Teams regress into feature factories when product knowledge decays faster than they can reuse it.
A customer interview happens, then disappears into notes. A design review surfaces a critical tradeoff, then gets buried in chat. An engineer discovers a constraint during implementation, but the next team rediscovers it months later. Discovery doesn't fail only because teams skip it. It fails because the learning doesn't stay durable.
That is the hidden tax behind weak discovery vs delivery product management.
Product memory is an operating advantage
The teams that improve fastest usually have one thing in common. They can retrieve past reasoning without archaeology. They know what was tested, what was rejected, which edge cases mattered, and where implementation constraints shaped the final call.
A real system of record matters more than another folder full of artifacts. Figr's AI documentation points toward the right problem to solve: organizing product knowledge so insights don't vanish across sessions, tools, and handoffs.
The Visual Context Graph makes knowledge reusable
The useful model here is the Visual Context Graph. It connects five layers of product understanding so discovery and delivery can work from shared memory instead of isolated files.
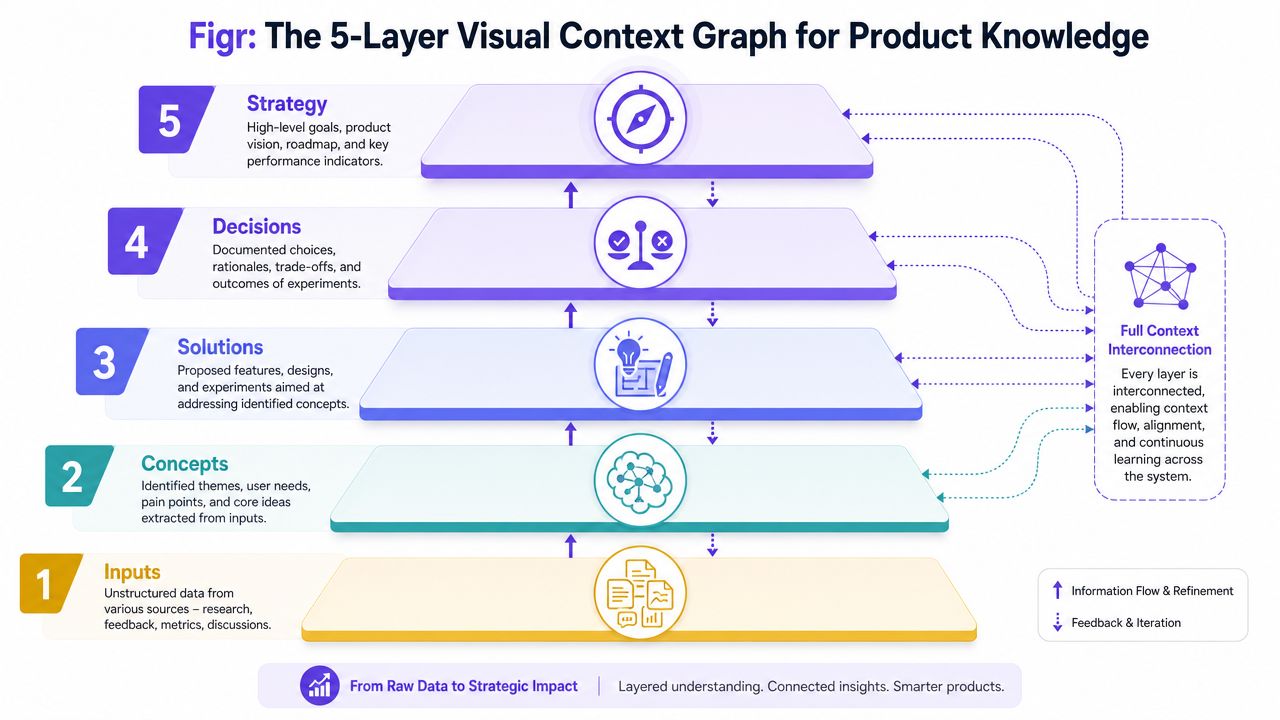
The five layers are:
Visual context
Screens, frames, layouts, and product structure people can inspect directly.
Behavioral context
Recordings, flows, click paths, and signs of how users move through the product.
Design System context
Tokens, components, variants, and the usage rules that shape coherent UI decisions.
Product Knowledge context
PRDs, research, prior decisions, rationale, and the evidence behind them.
Implementation context
Code constraints, technical realities, and the limits that affect what can be shipped.
Why this matters beyond one project
Here's the zoom-out moment. Product organizations don't usually fail from lack of ideas. They fail from poor memory and expensive relearning.
When knowledge is scattered, every roadmap cycle starts over. Teams repeat interviews, revisit settled arguments, and rebuild context in meetings that should have been decisions. A connected knowledge layer changes that. It turns discovery from a temporary activity into a compounding asset.
The result is better than documentation for its own sake. Product Managers can ask sharper questions. Designers can explore inside real constraints. Engineers can challenge proposals earlier. Delivery gets cleaner because discovery left a visible trail.
If your team is always shipping and never thinking, start by fixing the system that separates learning from execution. Try Figr if you want a context-aware way to turn product knowledge into testable artifacts and delivery-ready outputs.
Discovery and delivery don't need to compete for time. They need a shared operating model.
The core pattern is simple. Discovery reduces uncertainty. Delivery scales commitment. Teams get stuck when they overfund one and starve the other.
AI makes that imbalance harder to excuse now because the cost of exploration has dropped. Product Managers can test earlier, compare more paths, and preserve context instead of rebuilding it from memory. That's the strategic shift.
If I were tightening this tomorrow, I wouldn't start with a new framework deck. I'd pick one upcoming roadmap item, write down the riskiest assumptions, create the fastest artifact that could test them, and only then move into committed build work.
That one move is often enough to break the feature factory habit.
FAQ
Is discovery vs delivery product management really a tradeoff
Yes, but it's a manageable one. You're balancing learning and execution, and the right mix depends on how much uncertainty still exists.
How do I know if my team is over-indexed on delivery
I look for recurring rework, weak adoption after launch, and backlog items that entered build without clear evidence. Those are strong signals that shipping outran learning.
Should discovery and delivery have separate owners
I wouldn't separate ownership if I can avoid it. One product team should own both, or handoffs start replacing accountability.
Can AI replace product discovery work
No, and I wouldn't want it to. AI can reduce the cost of making artifacts, exploring options, and organizing context, but judgment still belongs to the team.
What's the first thing to change next week
Start with one active initiative. List the riskiest assumptions, run a lightweight test, and don't let the item move deeper into delivery until the biggest unknowns are narrower.