
A few years ago, Stripe surveyed a thousand developers and a thousand C-level executives across five countries. One finding stood out. The average developer spends 17.3 hours per week on maintenance, debugging, and fixing things that should've worked the first time. That's 42% of their week. Not building. Redoing.
The study estimated this pattern drains $300 billion in global GDP annually. But here's the part nobody talks about: within most teams, that number is invisible. It doesn't show up as "rework" on any ticket. It gets filed as a bug fix, a design revision, a "quick clarification." It blends into the sprint so naturally that it starts to feel like the job itself.
It's not.
The Feature That Was "One Screen"
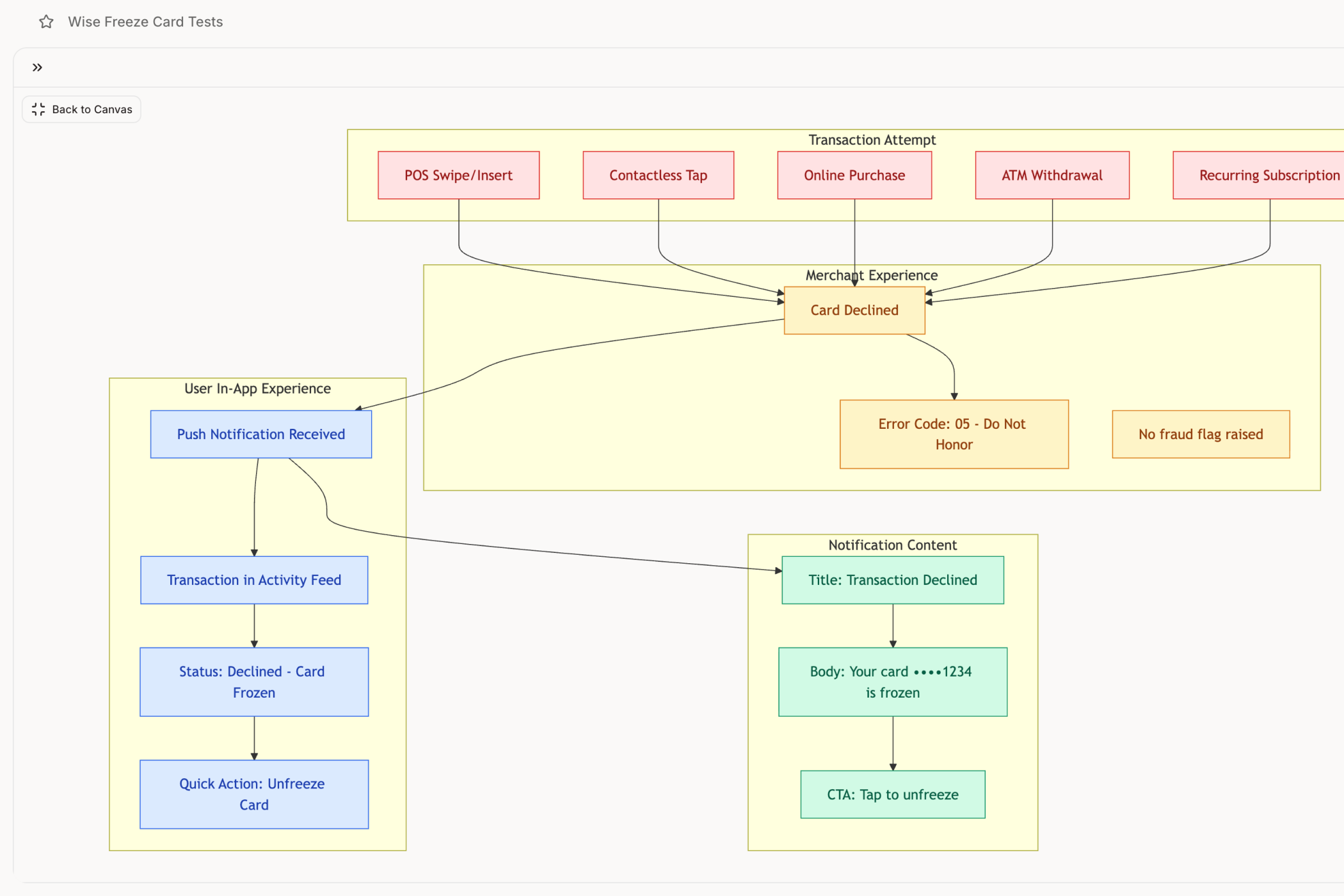
Every PM has lived this one. You spec a feature that sounds simple. Take something like freezing a payment card. A toggle, a confirmation, done. Maybe two screens.
Then someone starts asking questions. What happens when the user freezes their card while a pending transaction is processing? That charge doesn't just vanish. The UI needs to communicate that the card is frozen but the payment will still clear. What about a recurring subscription that charges tomorrow? Does it bounce? Retry? Queue? Each answer needs its own screen state, its own copy, its own recovery flow.
By the time you map it properly, that "one screen" feature has nine distinct states. When Wise's card-freeze flow was mapped end to end, those nine states were real: pending transactions, recurring charges, freeze-then-report-lost, partial freeze for a single merchant. And every state that surfaces during development instead of during planning becomes a full cycle: design it, review it, build it, test it.
This is the anatomy of rework. Not a failure. A timing gap.
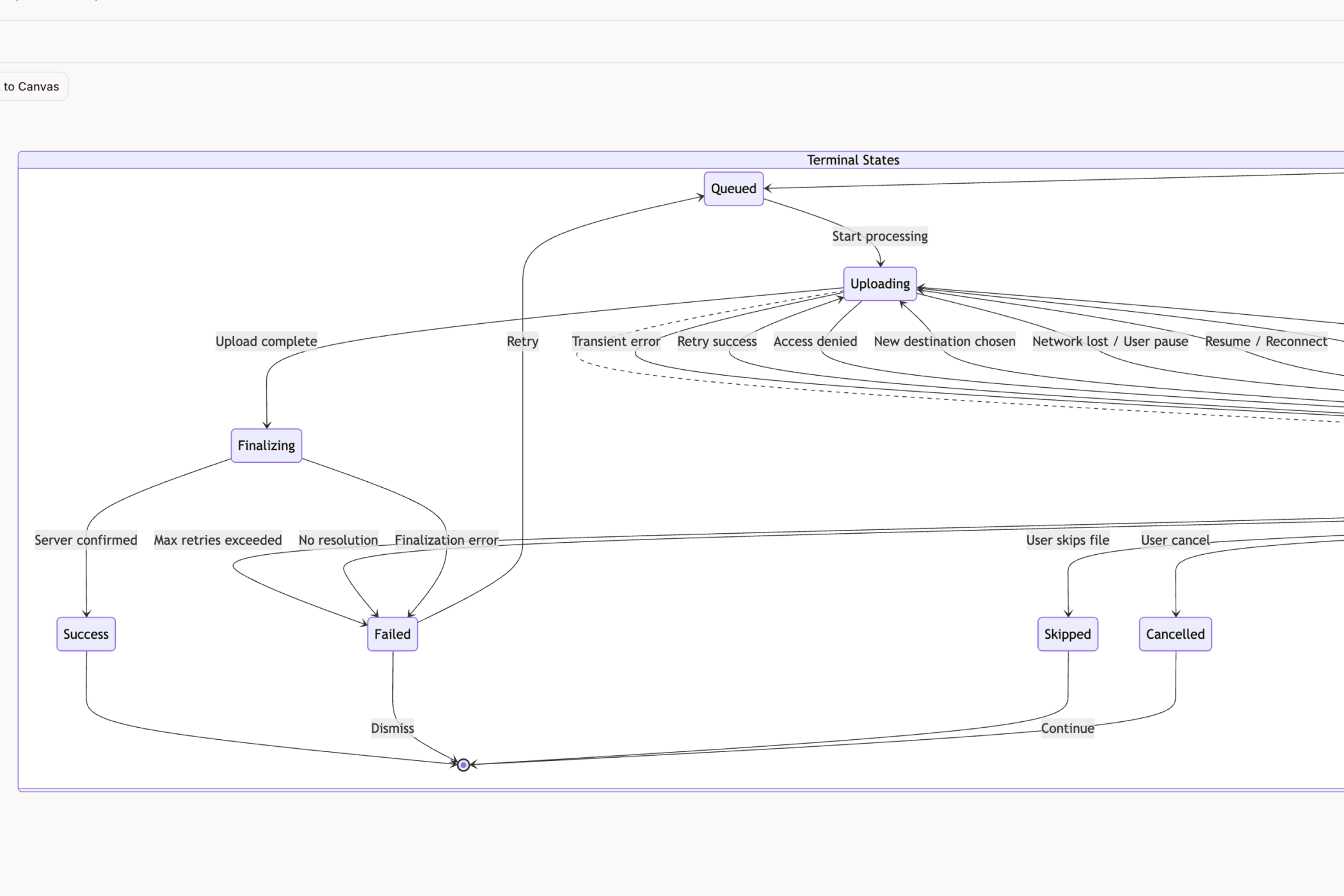
File upload has the same shape. When Dropbox's upload flow was properly mapped, 14 failure scenarios emerged. Network drops mid-transfer. Duplicate filename conflicts. Storage quota reached during a batch upload. A team that discovers those one at a time during QA spends two to three days per state, easily 28 to 42 engineering days across sprints. A team that maps them upfront builds them as part of the original spec.
Same code. Same states. Dramatically different calendar cost.
Rework Is Slower Than Building New
Here's something most product leaders don't realize. Rework isn't just duplicate effort. It's actually slower than the original build.
When you rework code, you're not writing from scratch. You're navigating decisions already made, trying to preserve what still works while changing what doesn't. Developer productivity on rework runs measurably lower than on new code, which is why a feature that should've taken five days to build right ends up taking twelve when you build it and then fix it.
Google's DORA research program put a broader number on this. Their analysis found that the average team reworks about 26% of its code before release. For a medium-sized engineering organization, that adds up to roughly $4.7 million a year in wasted effort.
These aren't dramatic numbers for dramatic effect. They're just what happens when complexity shows up late. A feature gets specced as three screens. It actually needs twelve. The gap between three and twelve is where the budget goes.
Why It Stays Invisible
The reason rework is so hard to see is that it looks exactly like regular work. New tickets. Same standup updates. Same Jira columns. A PM reading the board would never know that three of the five active tickets exist only because the spec was incomplete.
There's a language problem too. Rework rarely gets called rework. It gets called "iteration." It hides behind phrases like "we need to revisit this" and "requirements evolved." It has a great cover story. But iteration means improving something based on new learning. Rework means redoing something because the right information hadn't reached the right person at the right time. That distinction matters, because one is healthy and the other is preventable.
One Question, Three Sprints
You don't need a new process to start measuring this. You need one question at the end of each sprint:
"What did we revisit this sprint that we could have mapped before we started building?"
Write down the answers for three sprints. The patterns cluster fast. Unspecified states. Visual mismatches where a prototype didn't look enough like the live product, turning a stakeholder review into a conversation about fonts instead of concepts. Context that hadn't traveled from one team member to another before design started.
Most teams find that 15 to 30% of their sprint capacity goes to rework. That range is consistent across almost every team I've seen track it.
What the Number Makes Possible
"This sprint felt heavy" doesn't lead anywhere useful. "22% of our Q1 went to revisiting features because of unspecified states" tells you exactly where to invest.
Decades of software engineering research point to the same conclusion: among every approach teams have tried to improve efficiency, catching things earlier in the product development lifecycle gives the highest return. Not faster tooling. Not more engineers. Just moving the thinking upstream: mapping flows, writing test cases before design starts, specifying the twelve states instead of the three.
Most teams don't have dozens of rework problems. They have three or four patterns that repeat every sprint. Once you see them and attach a number to them, they're surprisingly fixable.
The hardest part is just starting to count.
Figr helps product teams surface edge cases, map flows, and build prototypes grounded in your actual product, so the thinking happens before the building. See real examples →