
A late design change rarely stays inside the frame where it started, and I've watched that truth wreck otherwise healthy product schedules.
Last week, I watched a Product Manager call a change “small” because it touched one settings screen. By the next standup, engineering had reopened API assumptions, QA had to rethink test coverage, and support documentation was already wrong. That's the current shape of the problem: what looks like a tidy design revision usually arrives as cross-functional churn.
The fix starts when teams stop treating rework as a design nuisance and start treating it as a systems cost. Tools and workflows that ground decisions in real product context, especially state coverage, prior decisions, design system rules, and implementation constraints, help teams catch the expensive questions before they become merged code and missed dates.
Why Does a Small Design Change Never Feel Small
A small design change never feels small because the interface is only the visible edge of a much larger dependency graph.
I call this Rework Gravity. It's the invisible pull a change creates once it enters a live product. The moment a designer updates one state, nearby decisions start moving too. Copy changes affect validation. Validation affects backend responses. Backend responses affect empty states, retries, analytics events, support scripts, and release notes. Everyone feels the pull, even if the ticket still looks harmless.
That mismatch between appearance and effort is why the cost of design rework gets underestimated so often.
Rework starts where certainty was assumed
Teams often don't get blindsided by obviously massive redesigns. They get blindsided by requests that sound reasonable in a planning meeting.
A few common examples:
A new field in onboarding becomes data model changes, mobile layout adjustments, error messaging, localization checks, and revised funnel tracking.
A pricing page tweak becomes entitlement logic changes, billing edge cases, experiment updates, and sales enablement revisions.
A permissions update becomes role-state complexity, admin exceptions, audit history changes, and more QA paths than anyone expected.
The basic gist is this: software products are dense with implied behavior. Visual change often masks logic change.
Practical rule: If a design change alters user choice, system response, or access conditions, treat it like a workflow change, not a screen change.
I've seen Product Managers get into trouble when they estimate only the visible artifact. The mock changed in an afternoon, so the work feels small. But the mock is just the receipt. The actual bill lands across engineering, QA, analytics, documentation, and handoff friction.
That's why solid design-to-dev handoff best practices matter more than polished screens alone. The handoff has to carry intent, states, assumptions, and constraints, or engineering will rediscover them the hard way.
The hidden tax is focus fragmentation
Rework doesn't just consume build time. It breaks sequence.
When engineers return to code they thought was done, they reload context. When designers reopen flows they mentally closed, they interrupt current work. When QA has to re-run a suite because one “minor” change touched shared components, the release train slows for everyone. None of that shows up neatly in the original ticket.
At this point, teams usually make the wrong call. They ask, “How many hours will the fix take?” A better question is, “What work now has to move because of this fix?”
That question catches Rework Gravity in motion.
Why intuition fails here
People are bad at estimating chain reactions. We're much better at estimating the object in front of us than the system around it. A Product Manager sees one new requirement. Engineering sees state branching. QA sees regression risk. Support sees changed behavior they'll have to explain next week.
No one is wrong.
They're just looking at different parts of the blast radius.
How to Calculate the Real Cost of Design Rework
You can calculate the real cost of design rework only when you count disruption and delay, not just logged engineering hours.
Direct effort is commonly tracked due to its defensibility. A reopened ticket has hours. A sprint slip has dates. However, the full burden typically involves context switching, reprioritization, and work that never ships because the team had to revisit something old.
A simple working formula helps:
Cost of design rework = (Engineer hours × fully loaded cost) + team distraction factor + opportunity cost of delay
That formula won't give you perfect finance-grade accounting. It will give you something far better for day-to-day product work: a shared language for discussing why “just one more change” is rarely cheap.

Start with the direct labor you can see
The first part is straightforward. Count the engineers, designer, QA, and Product Manager time needed to revisit the work. Include review, re-implementation, retesting, and re-approval. If a change reopens architecture or data questions, count that too.
Then add the work around the work:
Reload time: People need to remember prior decisions.
Coordination time: Slack threads, review calls, and revised specs appear.
Validation time: QA reruns paths that were previously closed.
Communication time: You update docs, support notes, and release messaging.
This is what I mean when I tell teams that rework is an accounting problem before it becomes a planning problem. If you count only code changes, you'll report a cheap fix. If you count the full path back to confidence, you'll report the actual one.
Use construction as a reality check
Physical industries have measured this longer than software teams have. A foundational Construction Industry Institute study found that deviations leading to rework, redesign, repair, or replacement averaged 12.4% of total installed project cost across nine industrial projects, and design changes, errors, and omissions accounted for 79% of deviation costs and 78% of the total number of deviations. The same analysis put design deviations at 9.5% of total installed project cost, compared with 2.5% for construction deviations, which is a strong signal that upstream design issues dominate the burden in complex systems, as detailed in the Construction Industry Institute research on quality deviations.
Software isn't construction, but the pattern is familiar. Late design mistakes don't stay in design. They travel downstream, where every correction costs more because more people and dependencies are already involved.
A back-of-the-napkin model Product Managers can use
When I need to make the case quickly, I use a three-part estimate:
Direct rework covers reopened design, engineering, QA, and review cycles. This is the visible spend.
Distraction cost covers context switching, interrupted sprint plans, and dependency reshuffling. This slows unrelated work.
Delay cost covers missed release windows, postponed experiments, and deferred roadmap items. This is where strategy gets hit.
That last row is usually the one stakeholders forget. A delayed release doesn't just move a date. It moves feedback, revenue learning, adoption learning, and confidence.
If you want a more structured way to make this visible, this guide to measuring rework for product teams is useful because it forces the conversation beyond “how long will the fix take?”
Rework feels small when you price the task. It feels expensive when you price the interruption.
The Ripple Effect When Rework Becomes a Cultural Problem
Repeated rework becomes a cultural problem when the team stops trusting that “done” actually means done.
A friend at a Series C company described a release cycle that felt cursed. The designer would present a polished flow, engineering would build to spec, and then a late stakeholder comment would reopen the logic after implementation had already started. No single change was catastrophic. The pattern was.
After a few rounds, the team changed its behavior.
People start protecting themselves
Engineering got cautious. Designers added extra states they weren't asked for, just in case. Product wrote longer tickets to defend against ambiguity. Review meetings grew because nobody wanted to be blamed later for missing something obvious.
That's the first cultural shift: teams stop building forward and start building defensively.
You can feel it in the room. A simple discussion about one flow becomes a negotiation about future reversals. People aren't debating the product anymore. They're trying to predict who might reopen the decision next week.
Trust erodes in quiet ways
Nobody usually says, “We have a rework culture.” They say smaller things.
“Let's wait before coding, this may change.”
“I don't want to sign off until legal sees it.”
“Can we keep this flexible for now?”
“We should probably build the backup version too.”
Reasonable? Sure.
Expensive? Very.
I've seen teams lose momentum this way without missing a dramatic deadline. The damage shows up as hesitation. The next project starts slower because everyone remembers what happened on the last one. The team becomes less willing to commit, less clear in reviews, and more likely to over-design or over-build for protection.
The visible cost of rework is the reopened task. The human cost is the loss of conviction.
Burnout grows when effort keeps getting erased
People can handle hard work. What wears them down is disposable work.
A Product Manager can survive a difficult release if the team believes the struggle produced learning. That same team will burn out if they keep redoing solved problems because the system keeps surfacing critical questions too late. Designers feel like they're decorating uncertainty. Engineers feel like they're coding on wet cement. QA feels like the last defense against process debt.
This matters at scale because incentives drift. When late changes are normal, teams optimize for reversibility over clarity. They keep options open longer, postpone hard calls, and avoid locking decisions. That feels prudent in the moment. It also pushes more ambiguity downstream, where it gets more expensive and more political.
Culture follows economics.
If discovering issues late is tolerated, teams will design late-discovery behavior into the way they work.
What If You Could Map the Future Before Building It
Most rework happens because teams build the happy path first and discover the actual product later.
That habit sounds practical. Ship the core flow, then fill in the exceptions. But software products don't break on the happy path. They break in the states around it: empty, partial, loading, expired, denied, conflict, interrupted, imported, retried, and abandoned. Those states carry most of the downstream surprises.
Edge cases are where schedule risk hides
A release can look complete in mocks and still be fragile in reality. Why? Because the main path often covers only the cleanest version of user intent. Real users arrive with missing permissions, stale data, interrupted sessions, and contradictory goals.
That's why Edge Case Mapping matters. It gives teams a disciplined way to ask:
What states can this feature enter
What triggers each state
What does the user see
What does the system do
What must engineering, QA, and support know
A gallery example makes this concrete. A task approval card can look like a simple component until you enumerate all the possible product states around it. Approval pending, delegated, expired, blocked, already resolved, waiting on another approver, and more. The visual artifact is one card. The shipped behavior is a network of states.
Mapping the future changes the quality of debate
Reactive teams ask during QA, “What happens if this fails?”
Proactive teams ask during design, “Where can this fail, and who owns each response?”
That shift sounds subtle. It's not. It changes whether ambiguity gets discovered in a review meeting or in production. It also changes whether your discussions are abstract or grounded in user experience.
I'd rather sit in a planning review where someone argues about a rare failure state than in a launch review where the same issue appears as a blocker. Early discomfort is cheaper than late certainty.
A strong effective product strategy guide helps here because strategy isn't only choosing what to build. It's also deciding which states and failure modes deserve explicit treatment before work begins.
Better maps beat better guesses
Teams don't need a crystal ball. They need a map with enough fidelity to expose risk while decisions are still cheap.
That's where context-aware tooling can help. Instead of prompting from a blank canvas, teams can pull from live screens, prior decisions, design systems, research, and observed flows to surface likely branches and missing states earlier. The point isn't to predict every exception. It's to reduce the number of expensive surprises that survive until engineering or QA.
If you've ever had a sprint derailed by a permissions edge case nobody modeled, you already know the value of better maps.
Catching Rework Early with UX Reasoning
UX Reasoning catches rework early because it forces the team to think through intent, constraints, and state logic before anyone mistakes a draft for a decision.
A prompt can generate a screen. It can't reliably explain why that screen should behave a certain way under pressure, exception, or conflict. That missing middle is where brittle product work comes from. Teams jump from idea to artifact too quickly, and all the unresolved questions hitch a ride into implementation.
The missing middle between prompt and prototype
I think of UX Reasoning as structured pre-commit thinking. It asks what the user is trying to do, what the product must protect, and what tradeoff the team is willing to make.
A few examples:
If a user edits data mid-flow, which source of truth wins?
If a form partially saves, what promise are you making about recovery?
If permissions change during a session, does the interface degrade, block, or redirect?
If an action is high risk, what confirmation pattern matches the product's existing behavior?
These questions sound obvious after launch. Before launch, they often live in scattered memory.
For teams working through forms, auth, or transactional flows, I often point people to practical references on mobile form patterns and accessibility because form behavior is where hidden assumptions show up fast. Validation, keyboard states, field order, error recovery, and interruption handling can create far more rework than the initial layout suggests.
Shared context beats heroic memory
What works is a process where decisions, constraints, and prior rationale stay visible to the whole team. What doesn't work is depending on the one designer or Product Manager who “knows the history.”
That's where tooling becomes useful in a very specific way. Figr can ingest PRDs, research, analytics, live screens, design system patterns, and implementation constraints into a Context Pod so teams can reason from actual product context instead of isolated prompts. That helps turn loose assumptions into concrete artifacts like flows, edge case maps, test scenarios, and Figma-ready screens.
The value isn't that a tool thinks for the team. The value is that it reduces context loss.
Field note: Good UX Reasoning doesn't eliminate changes. It moves the expensive ones earlier, while they're still words, diagrams, and prototype decisions.
The review questions that catch trouble early
When I want to pressure-test a flow before engineering starts, I use questions like these:
State coverage: Which user-visible states exist beyond success?
Dependency check: What backend, policy, or analytics assumptions does this flow rely on?
Fallback behavior: What happens when data is missing, stale, or denied?
Decision memory: Where is the rationale documented so the team can revisit it later?
Testability: Can QA derive scenarios directly from the design artifact?
If your prototype can't answer those questions, it's not ready for confidence. It's ready for discussion.
That's why mastering prototype testing matters. Testing a prototype should reveal decision gaps before they harden into sprint commitments.
Why Design System Drift Is a Silent Rework Factory
Design system drift creates silent rework because inconsistent components spread hidden decisions into every new feature.
Drift is often considered a visual cleanliness problem. It's more expensive than that. Once the same interaction pattern exists in multiple forms, every new screen forces a fresh choice. Which variant is canonical? Which token is current? Which behavior does engineering implement? Small uncertainty repeats until it becomes a standing tax on delivery.
Drift is bad product data in disguise
Construction research offers a useful analogy here. An industry analysis cited by Autodesk and FMI estimated that bad data cost the global construction industry $88.69 billion in rework in 2020, and that miscommunication and poor project data accounted for 48% of all rework on U.S. construction jobsites, as summarized by ASCE's coverage of field rework and bad data.
Software teams create their own version of bad data when design systems stop reflecting reality. The component library says one thing, production shows another, and the latest file in Figma says something else again. Now every stakeholder is making decisions from a different map.
That's when rework stops looking dramatic and starts looking routine.
What drift looks like in practice
You'll recognize it quickly:
Buttons with the same label behave differently across flows.
Tokens exist but aren't trusted, so people override them.
Variant sprawl grows, and nobody knows which option is safe to reuse.
Engineering recreates patterns manually because the source artifacts feel unreliable.
I've watched this happen on teams with talented designers and disciplined engineers. Drift doesn't require incompetence. It only requires time, deadlines, and a few undocumented exceptions.
The expensive part is decision duplication
Every time a team revisits a pattern that should already be settled, it pays twice. First in the immediate design or build decision. Then again later when another team copies the wrong version.
That's why I find Figr on design system divergence useful as a framing reference. Drift isn't only a consistency issue. It's a rework generator because it multiplies ambiguity at the point of execution.
The fix usually isn't a giant cleanup project. It's tighter enforcement of tokens, clearer usage rules, and better visibility into what the product uses today. Teams need design systems that preserve judgment, not just component inventories.
How the Visual Context Graph Prevents Downstream Surprises
The Visual Context Graph prevents downstream surprises by connecting the layers of product context that teams usually review in isolation.
Most late-stage rework comes from a context gap. The screen looked fine, but the flow assumption was wrong. The pattern matched the library, but not the implementation constraint. The PRD described the goal, but not the system behavior that makes the goal real. Generic design generation struggles here because it starts from plausibility. Product teams need coherence.
A layered model solves that better than a pile of disconnected artifacts.
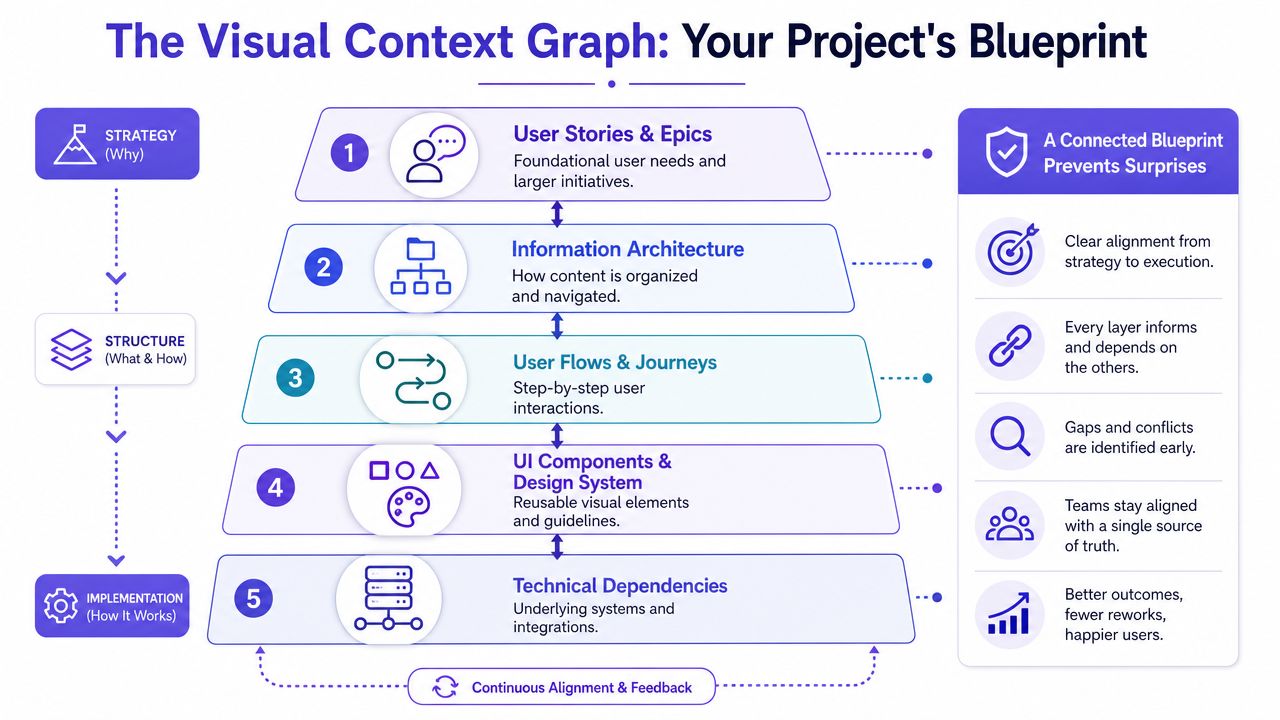
The five layers that matter
The Visual Context Graph has five connected layers:
Visual context
Existing screens, frames, layouts, and interaction patterns. This keeps new work visually grounded in the product users already know.Behavioral context
Recordings, flows, navigation paths, and observed usage behavior. This shows how people move through the product.Design System context
Tokens, components, variants, and usage rules. This reduces drift and narrows implementation ambiguity.Product Knowledge context
PRDs, research, decisions, acceptance criteria, and prior rationale. This preserves memory across teams and time.Implementation context
Code constraints, technical dependencies, and known system limits. This catches the “looks easy, builds hard” class of mistake.
When these layers stay disconnected, teams invent coherence manually. That's slow, and it fails under deadline pressure.
Here's a product walkthrough that makes the idea easier to visualize:
Why this reduces the cost of design rework
The reason this matters is simple. Rework thrives in seams.
A designer may see the current screen but miss the historical rationale. An engineer may understand the constraint but not the intended fallback state. A Product Manager may know the target metric but not the component rules that will shape implementation. Each person is informed. The team is still fragmented.
A connected context model changes the handoff quality. It helps teams generate and review artifacts that answer adjacent questions before they become blockers.
Downstream surprises usually aren't surprises to the whole company. They're facts that lived in one layer of context and never reached the others.
What changes in day-to-day work
When teams work this way, planning gets more concrete. Reviews focus on tradeoffs instead of interpretation. QA derives cases from state logic instead of reverse engineering intent. Engineering gets clearer constraints earlier. Product gets a better view of risk before dates harden.
That doesn't remove change from product development. It reduces accidental change, which is the kind that punishes schedules the most.
An Actionable Checklist for Your Next Release
The fastest way to reduce the cost of design rework is to change what your team asks before implementation starts.
You don't need a giant process overhaul to do that. You need a release checklist that forces hidden assumptions into the open while the work is still cheap to revise. I'd bring this into the next planning or kickoff meeting and walk through it line by line.

A practical pre-build checklist
Step 1. Map every user-visible state.
List the flow states before the PRD hardens.
Include obvious states: empty, loading, success, error
Include operational states: retry, timeout, partial completion, offline behavior
Include policy states: permission denied, role mismatch, expired access
Step 2. Write down what can change underneath the screen.
A stable mock can still sit on unstable logic.
Ask about dependencies: APIs, billing logic, permissions, analytics events
Ask about ownership: who approves behavior when the dependency changes
Ask about fallout: what else needs retesting if this assumption moves
Step 3. Price the interruption, not just the implementation.
Estimate the surrounding churn before committing the date.
Count direct work: design, engineering, QA, review
Count coordination: handoff updates, cross-team review, support prep
Count delay: what gets pushed if this work reopens late
Step 4. Turn rationale into an artifact.
If a decision lives only in someone's head, it will be rediscovered later.
Use short records:
Decision made
Tradeoff accepted
Constraint acknowledged
Open question deferred
Step 5. Force one pre-build edge case review.
Run a short review focused only on failure and exception paths.
Invite the people who'll absorb rework later:
Engineering for feasibility and system behavior
QA for scenario coverage
Support or ops for user-facing recovery implications
The checklist works because it changes timing
Teams do answer these questions eventually. The issue is when.
If they come up during implementation, they become blockers. If they come up in QA, they become scramble work. If users discover them first, they become trust debt. A checklist doesn't make the product simpler. It makes risk visible earlier.
That's usually enough to improve the conversation in one release cycle.
If your team is tired of relearning the same product context every sprint, try Figr. It helps teams work from existing screens, flows, design systems, docs, and implementation constraints so edge cases, state coverage, and handoff details show up earlier, when they're still cheap to change.
The hidden cost of design rework usually isn't one dramatic failure. It's the accumulation of reopened decisions, broken focus, and delayed learning across a release cycle.
The pattern gets easier to manage once you give it a name. Rework Gravity explains why small changes keep dragging in more work than expected. Edge Case Mapping and UX Reasoning help teams catch that pull before it reaches code. A connected view of product context helps keep decisions from fragmenting across files, tools, and memory.
The bigger lesson is economic. Teams don't suffer from change itself. They suffer from discovering necessary change too late.
Start with one release. Map the states. Record the rationale. Price the interruption. Then see which “small” changes still look small.
FAQ
How do I explain the cost of design rework to stakeholders
I'd avoid abstract quality language and show the chain reaction. Tie the change to reopened engineering, retesting, context switching, and delayed roadmap work, not just design hours.
What usually causes the most expensive rework
In my experience, it's unresolved logic hiding behind polished screens. Permissions, validation, fallback behavior, and design system inconsistency tend to surface late and spread fast.
Can't agile teams just iterate their way through this
Yes, but iteration works best when teams are learning from users, not rediscovering avoidable internal gaps. Healthy iteration creates insight. Rework burns time on preventable ambiguity.
When should a Product Manager start looking for rework risk
I'd start during shaping, before delivery dates harden. If a flow changes user choice, backend behavior, or role logic, I'd assume rework risk exists until the team maps it.
What's the simplest first step for reducing design rework
Ask the team to list every state outside the happy path for the next feature. That single exercise usually exposes missing assumptions faster than another review meeting.