
It's 10:15 AM on Monday. The login failure bug from last sprint? It’s back. Engineering patched it, QA gave it the green light, and yet here it is again, polluting your error logs and infuriating users.
This isn't just a technical glitch. It's an echo.
It’s the classic symptom of a team fixing what they see, not what’s truly broken. We’re treating the cough, not the infection. This cycle of recurring issues is exhausting. It kills team morale and quietly drains resources that should be building new value. Honestly, learning how to reduce customer churn starts with digging deeper than the most obvious bug report.
The Hidden Cost of Surface-Level Fixes
Problems are not singular events. They are switchboards, with dozens of tiny connections leading to the one light that flashes red on your dashboard. Chasing that single light is a fool's errand. You have to trace the wiring back to the source.
Last week I watched a PM at a fintech company spend an entire quarter chasing a phantom performance issue. The app felt sluggish, but every single metric looked fine. After weeks of hitting dead ends, a junior engineer finally asked a simple question during a retro that kicked off a 5 Whys session. Turns out, the issue wasn’t in their code at all. It was a misconfigured caching layer updated by a third-party service months ago.
The 5 Whys isn't just another meeting on the calendar; it's a diagnostic tool. Think of it as a conversational scalpel for dissecting causality. It transforms the team from firefighters, endlessly battling the same blaze, into detectives tracing clues back to the source. This is what I mean: a good investigation doesn't just finger a suspect; it exposes the flawed system that allowed the crime to happen in the first place. This is also why having a solid grasp on spotting overlooked edge cases is so critical for preventing these issues from ever taking root.
The goal isn’t to find someone to blame. The goal is to find a process to fix. When "human error" is the answer, the real question becomes: Why did the system allow for that error to occur?
This approach fundamentally changes how a team sees its own work. It shifts the focus from short-term patches to building long-term resilience. So, the next time a bug from last sprint reappears, will your team reach for another band-aid, or will they start asking why?
Your Actionable 5 Whys Template and How to Use It
Theory is clean. Execution is messy. A 5 Whys template is your tool for cutting through that mess. Think of it less like a document and more like a structured conversation that forces clarity out of chaos. But like any good tool, its power is all in how you use it.
Let's get practical. The first move isn't even asking "Why?" It's defining the problem with surgical precision. A vague statement like "user engagement is down" is a dead end. It gives your team nothing to grab onto.
A strong problem statement sounds like this: "User session duration for trial accounts on the dashboard page has decreased by 22% in the last 14 days, according to our analytics."
Now that's a real problem.
The data makes it specific and undeniable. This whole process is about digging deeper than the quick, obvious fix. It’s about getting to the real breakdown.
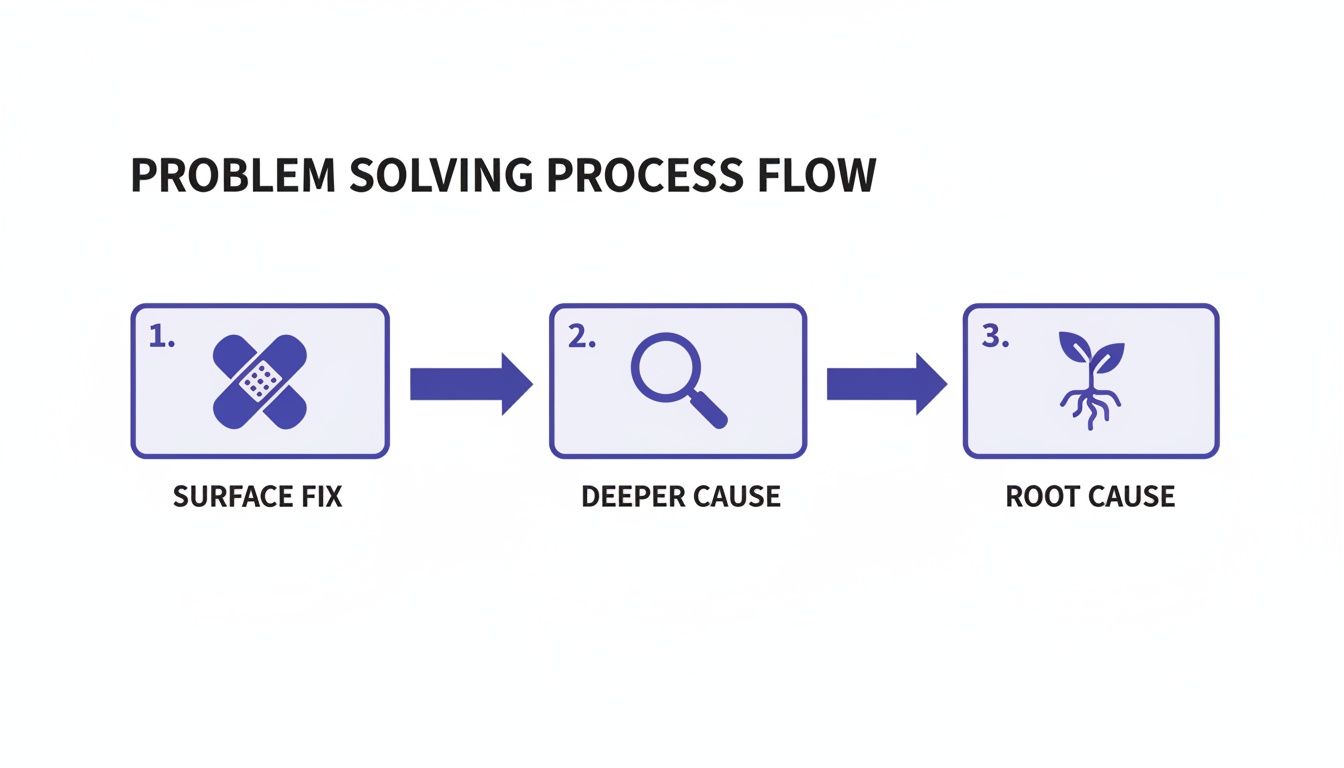
As the diagram shows, a surface fix is just a patch. It deals with the symptom. The real win comes from finding the underlying process failure that allowed the symptom to happen in the first place.
Assembling Your Crew
Your second critical step: get the right people in the room. This almost never means just engineers.
Imagine a simple login failure. To really understand it, you might need an engineer, the product manager who defined the requirements, the designer who created the error state, and the QA analyst who tested the last fix. Each person holds a different piece of the puzzle. Leave one out, and you create a blind spot.
The facilitator's main job is to keep the conversation pointed at the system, not at individuals.
A good 'Why' question uncovers a broken process. A bad one points fingers at a person. If an answer is "because the developer made a mistake," the only acceptable follow-up is, "Why did our process allow that mistake to be made and not catch it?".
That simple pivot changes everything. It turns a blame session into a productive analysis. This focus on systems thinking is a lot like the structured approach used for a thorough task analysis in UX design, where you map out every single step to understand the complete journey.
From the Factory Floor to Your Sprint Board
This isn't some new-age product trend. The 5 Whys technique has a long, proven history. It goes all the way back to Sakichi Toyoda in the 1930s and was later made famous by the Toyota Production System, becoming a cornerstone of their lean manufacturing revolution.
In his book The Toyota Way, Jeffrey Liker notes that this simple framework helped Toyota slash defect rates by up to 90% in some of its most critical processes. More recently, studies show that tech and manufacturing companies using structured RCA methods like 5 Whys see a 25-30% faster problem resolution time. You can explore the findings on operational excellence from Adobe Business if you want to dig into the data.
So, how do you actually run this play? Here's the breakdown.
- Problem Statement: Be brutally specific. Use data.
- Why #1: Why did this happen? (Focus on the direct technical event or user-facing symptom).
- Why #2: Why was that possible? (Now you're starting to look at the immediate process).
- Why #3: Why was that process in place? (Question the assumptions behind that workflow).
- Why #4: Why did we accept that as the standard? (This probes into team habits or historical baggage).
- Why #5 & The Root Cause: Why does our system operate this way? (You've usually arrived at a systemic issue: a gap in training, a missing QA step, a broken communication loop).
This structured digging is how you turn a vague frustration into a clear, actionable insight. It’s how you stop fixing the same bug for the third time and finally solve it for good.
Real World Examples from Product Teams
Theory is a map, but the real world is the territory. It's full of unexpected turns. A good 5 Whys template is your compass in that territory, especially when you're under pressure to ship and something breaks. Let's move from the abstract and see how this plays out with real product teams.
A friend at a Series C company told me they used this exact method when their checkout conversion dropped by a staggering 15% overnight. Panic set in. The initial suspect was a recent deployment, but rolling it back changed nothing. It was a 5 Whys session that saved them from a week of frantic, misguided debugging.
The most painful problems often hide in plain sight, disguised as something else entirely. Here are three detailed scenarios where a 5 Whys analysis uncovered a critical insight that a surface-level fix would have completely missed.
The Bug That Wasn't a Bug
A recurring production bug kept popping up every few weeks. An image uploader would fail for a small group of users, throwing a vague server error. Engineering would patch it, QA would verify the fix, and then, like clockwork, it would return.
Here’s how their 5 Whys session unfolded:
- Problem: The image uploader fails intermittently for users on slower connections.
- Why 1? A timeout exception is being thrown before the upload completes. (The technical symptom)
- Why 2? The client-side timeout is set to 15 seconds, but the server-side timeout is 30 seconds. (A system conflict)
- Why 3? The frontend and backend tickets were worked on by different engineers who didn't sync on the timeout values. (A communication gap)
- Why 4? There was no explicit requirement in the ticket to align timeout values. (A documentation failure)
- Why 5? Our handoff process from PM to engineering doesn't include a technical spec review for non-functional requirements like this. (The root cause)
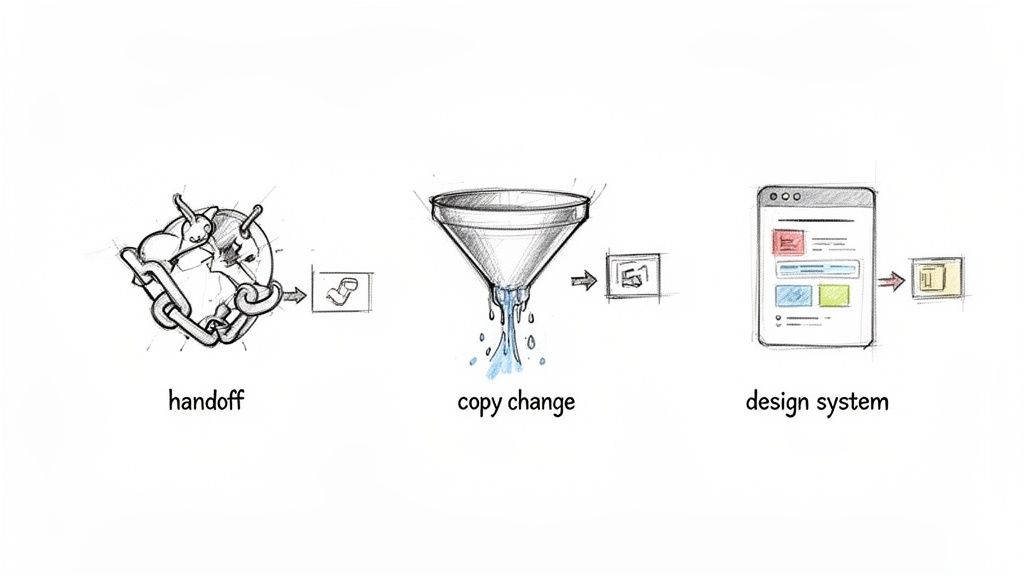
The team had been fixing the code. But the root cause was a broken process. The real fix wasn't another line of code; it was adding a mandatory "Technical Handoff" checklist to their Jira workflow. Problem solved, for good this time.
The Silent Drop-Off
An analytics alert flagged a sudden 20% drop in the onboarding funnel. Users were getting to step three and then vanishing. The team's first assumption? A recent feature release must have introduced a bug.
Let’s trace the questions:
- Problem: User drop-off at step three of onboarding increased from 5% to 25% on Tuesday.
- Why 1? Users are not clicking the "Connect Your Calendar" button. (The user behavior)
- Why 2? The button's purpose seems unclear to users based on session recordings. (A UX hypothesis)
- Why 3? The copy on that screen was changed two sprints ago from "Connect Your Calendar" to "Grant Permissions." (A specific change)
- Why 4? The marketing team requested the copy change to align with their new "Security First" messaging campaign. (An external influence)
- Why 5? We have no process for UX to review marketing-initiated copy changes that affect the core product flow. (The root cause)
The issue wasn't a bug, it was a word. The team had optimized for brand messaging at the expense of clarity, revealing a silo between product and marketing. They learned that even small copy changes need to be treated like any other product change. A valuable lesson, and another reason why learning how to collect customer feedback continuously is non-negotiable.
The Outdated Component
A new filter feature was causing the entire dashboard to lag. It worked, but it was sluggish and felt broken. The engineers insisted their logic was efficient.
The 5 Whys revealed a different story:
- Problem: The new "Filter by Date" feature has a 3-second UI lag.
- Why 1? The date-picker component is re-rendering the entire dashboard on every selection. (The technical cause)
- Why 2? The component being used is an old, deprecated one from our design system. (A legacy issue)
- Why 3? The designer who worked on the feature used an older version of the Figma UI kit. (A tooling problem)
- Why 4? Our process for updating designers on new UI kit versions is an inconsistent Slack announcement. (A communication breakdown)
- Why 5? We haven't established a single source of truth or a formal update process for our design system. (The root cause)
The problem felt like an engineering issue, but it was a design operations failure. The fix was to implement a versioning system for their design library and create a formal communication plan for updates, saving countless future hours of rework.
Common Pitfalls and How to Sidestep Them
The 5 Whys technique looks like a straight line on paper. Ask a question, get an answer, repeat five times. Simple, right?
In practice, it’s more like navigating a maze in the dark. That beautiful simplicity is deceptive, making it incredibly easy to take a wrong turn and end up right back where you started, only more frustrated.
The most common failure isn't a lack of effort; it's a lack of depth. Teams often stop at the third "Why," mistaking a symptom with a bit more context for an actual root cause. This premature conclusion feels like progress, but it’s a trap. It’s the organizational equivalent of taking a painkiller for a broken bone: you’ve muted the signal, not healed the injury. This is the fast, politically safe route, and it's ultimately the most expensive one.
The Blame Game Versus System Failure
I watched a product team last quarter analyze a critical data sync failure. Their second "Why" led them to a specific engineer who had pushed a faulty script. The room went quiet. The analysis stopped right there, the conclusion hanging in the air: human error.
This is the single most dangerous dead end in any root cause analysis.
The basic gist is this: when your analysis ends with a person, you’ve failed. People don't fail, processes do.
The correct follow-up question is always, “Why did the process allow for that human error to occur and go uncaught?” This reframes the entire exercise. It zooms out from the individual to the system. Was there no automated pre-deployment check? Was the code review process rushed? Was the engineer working with unclear requirements? That’s where the real gold is.
When you hit a messy system-level problem, you'll find that managing its downstream effects is a skill in itself. It helps to understand how to prevent scope creep so these fixes don't derail your entire roadmap.
Vague Answers and The Wrong Audience
Another classic pitfall is accepting vague, hand-wavy answers. "Because we were in a hurry" or "because of a communication breakdown" are not answers. They are symptoms disguised as conclusions.
A good facilitator has to push back, gently but firmly. "Why were we in a hurry? What specific part of the communication process failed?" Insist on answers that are concrete and actionable.
Equally damaging is having the wrong people in the room. If you’re investigating a UX issue and have only engineers present, you’re flying blind. You’re missing the context from the designer who created the flow and the product manager who wrote the requirements. The answers you get will be technically correct but systemically incomplete.
The quality of your root cause analysis is a direct reflection of the quality of your questions and the diversity of the perspectives in the room.
Data confirms the power of getting this right. Within Six Sigma's DMAIC framework, using a root cause analysis 5 whys template has been shown to reduce defect recurrence by up to 50%. Yet, the method has its limits. Without rigorous data validation and a commitment to digging past easy answers, its accuracy can drop significantly in complex scenarios. You can discover more insights about root cause analysis from Tableau and its statistical backing.
Sidestepping these common pitfalls is the first step toward turning this simple tool into a powerful engine for building more resilient products.
From Diagnosis to Action: Putting Your 5 Whys to Work
An analysis is a fossil record: a perfect picture of what went wrong. But it's useless if it doesn't inspire change. The gap between a finished 5 Whys template and a tangible improvement is where most teams lose momentum. The insight fades, the ticket gets closed, and the broken process remains.
This is where diagnosis has to become action.
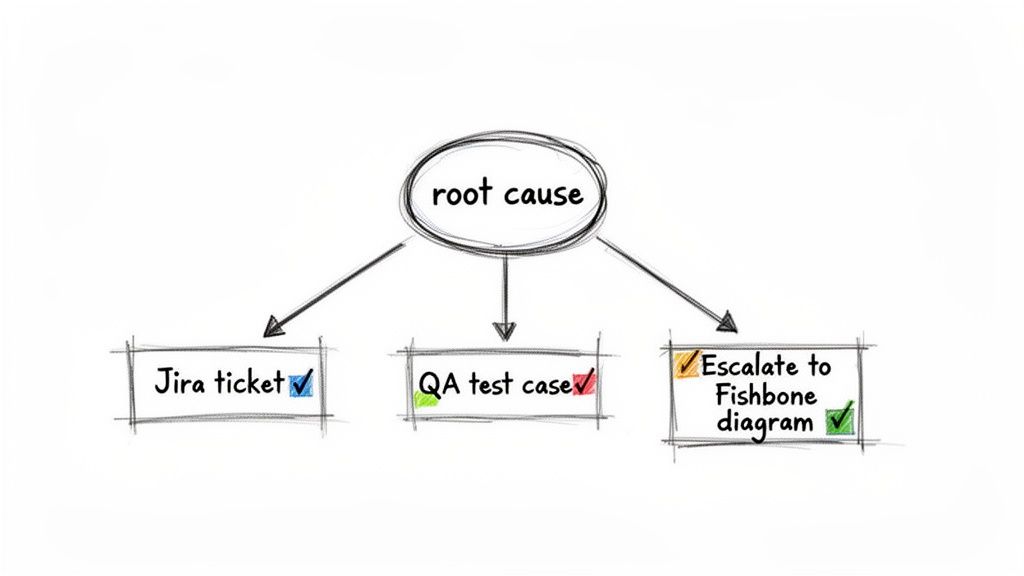
A completed root cause analysis shouldn't just be an interesting document. It's the blueprint for specific, actionable work. For every root cause you identify, you must create a corresponding artifact that makes the problem harder to repeat.
From Insight to Implementation
Translating your findings is the most critical step. Don't just close the investigation; open the tickets that will prevent its sequel.
- Create Specific Jira Tickets: The output isn't a vague task like "Fix the handoff process." It's a ticket titled, "Add 'Technical Handoff Checklist' to Epic Template" with crystal-clear acceptance criteria detailing exactly what that checklist must include.
- Generate QA Test Cases: Your analysis reveals a specific failure point. A QA engineer can take that insight and immediately write a test case that explicitly checks for that failure in the future, hardening your regression suite against a known weakness.
- Update Your Documentation: Was the root cause a missing step in your team's onboarding guide or an outdated process doc? Don't just talk about it, create a ticket to update it immediately.
This mechanical process of creating work ensures the insight survives the chaos of the next sprint planning meeting.
When the 5 Whys Isn't Enough
Sometimes, the problem isn't a single thread you can neatly pull. It’s a tangled knot. I once watched a team try to apply the 5 Whys to a platform-wide performance degradation issue. Their chain of questions branched in five different directions, from database queries to CDN configurations to a recent third-party library update.
That's the signal to escalate your toolkit.
The 5 Whys is a scalpel, perfect for a single, deep incision. For problems with multiple contributing factors and complex interdependencies, you need a different instrument, like a Fishbone (Ishikawa) diagram.
How do you know when to switch? Ask yourself: does this problem feel linear or systemic? If your second "Why?" already has three valid, competing answers, you've outgrown the 5 Whys for this particular issue. Acknowledging this prevents you from forcing a complex problem into an overly simple framework.
In short, while the 5 Whys is a powerful tool, it's just one of many approaches. To broaden your toolkit for diagnosis and action, consider exploring other effective creative problem solving techniques. Using the right level of analysis for the problem at hand isn't just efficient; it's the mark of a mature, high-functioning product team.
Common Questions (and Straightforward Answers)
A 5 Whys template is a fantastic starting point, but it's not a magic wand. Once you get your team in a room, the real-world questions start popping up. Here are the ones I hear most often.
How Do You Know When You've Reached the Real Root Cause?
You're probably there when the answer to a "Why?" points to a broken process, not a person. It’s a subtle but critical shift. The final answer should be something the team can actually grab onto and fix.
Here’s a simple gut check: if you can't spin the final "Why" into a concrete Jira ticket or a clear action item, you haven’t dug deep enough. A genuine root cause is almost always systemic. Fixing it shouldn't just solve this one bug; it should prevent an entire class of similar problems from ever happening again.
What's the Ideal Group Size for a 5 Whys Session?
Keep it focused. The magic number is usually between three to seven people. This is small enough to avoid turning into a debate club but large enough to get the perspectives you need.
You absolutely must have the people who live and breathe the problem in the room: think product, engineering, and QA. Maybe design, depending on the issue. Too many cooks in the kitchen will slow you down and dilute the focus. Too few, and you risk missing that one critical piece of the puzzle.
Pro Tip: If you can, bring in a designated, neutral facilitator. Their only job is to keep the conversation objective and moving forward, which is invaluable when tensions are high.
Can We Use This Template for Big-Picture Business Problems?
Absolutely. While the 5 Whys got its start on the factory floor, it's a remarkably flexible tool. I’ve seen it work wonders on tough business questions.
Think about problems like, "Why did our new feature miss its adoption target by 30%?" or "Why has our customer churn rate ticked up again this quarter?"
The process is exactly the same. You start with a clear, data-backed problem statement and just keep asking "Why?" until you unearth the systemic issues driving the numbers.
Ready to stop patching symptoms and start solving core problems? Figr uses AI to help you find edge cases, map out user flows, and generate QA test cases right from your designs. It’s the fastest way to turn product thinking into production-ready work. Design confidently and ship faster with Figr.